SmartEmbed: A Tool for Clone and Bug Detection in Smart Contracts through Structural Code Embedding
SmartEmbed: A Tool for Clone and Bug Detection in Smart Contracts through Structural Code Embedding
论文题目:(2019-ICSME)SmartEmbed: A Tool for Clone and Bug Detection in Smart Contracts through Structural Code Embedding——通过结构代码嵌入在智能合约中进行克隆和错误检测的工具
论文引用:Gao Z, Jayasundara V, Jiang L, et al. SmartEmbed: A Tool for Clone and Bug Detection in Smart Contracts through Structural Code Embedding[C]//2019 IEEE International Conference on Software Maintenance and Evolution (ICSME). IEEE, 2019: 394-397.
代码开源:beyondacm/SmartEmbed
一、主要内容
1.1 研究背景
以太坊已成为广泛使用的平台,以实现基于区块链的安全金融和业务交易。但是,以太坊的一个主要问题是其智能合约的安全性。智能合约中许多已确定的错误和漏洞不仅给维护区块链提出了挑战,而且还导致了严重的财务损失。迫切需要更好地帮助开发人员检查智能合约并确保其可靠性。
近年来,随着分布式分类账(又称区块链)中加密货币的采用和发展,以太坊作为区块链平台越来越受到关注。以太坊平台的核心是智能合约,智能合约是一种计算机程序,可以在满足特定的预定义条件时触发以执行任何任务。以太坊平台的主要关注点是智能合约的安全性,区块链中的智能合约通常涉及价值数百万美元的加密货币(例如DAO1,Parity2等)。此外,与传统软件程序不同,智能合约代码在部署后是不变的。智能合约无法更改,但在智能合约中发现任何安全问题时可能会被杀死。这给区块链维护带来了挑战,并极大地激发了黑客发现和利用智能合约中潜在问题的动力,因此,非常需要在部署之前检查并确保智能合约的健壮性。
1.2 相关工作
许多先前的工作已经研究了智能合约的漏洞检测(bug detection),主要的缺点如下:
- 所有这些现有工具都需要人工专家定义的某些错误模式或规范规则。
- 编写新规则并构造新的检查器以应对攻击者创建的新错误和漏洞可能太慢且成本太高。
- 这些漏洞检测的手段(如符号执行、模糊检测等)资源消耗过大。
1.3 主要成果
本文提出了一个名为SMARTEMBED的Web服务工具,该工具基于深度学习的代码嵌入和相似性检查技术,通过比较以太坊区块链中现有Solidity代码的代码嵌入向量与已知错误之间的相似性,来帮助Solidity开发人员在智能合约中查找重复的合约代码和克隆相关的漏洞。
以太坊区块链收集的超过22K个Solidity智能合约,发现合约代码的克隆率接近90%,远高于传统软件。将SMARTEMBED应用于这些智能合约,根据我们的小型bug数据库(small bug database),可以准确、有效地识别 194 个与clone相关的错误,准确率达96%。
二、设计实现
2.1 设计思想
SMARTEMBED的主要思想有两个方面。
- 代码嵌入(Code Embedding):利用基本程序分析和许多开源智能合约的可用性,我们通过改编自单词嵌入(word embeddings)的技术,将每个代码元素和漏洞模式(bug pattern),包括它们的词法、句法乃至某些语义信息( lexical syntactical)自动编码为数值向量(numerical vectors)。
- 相似性检查(word embeddings):利用智能合约中代表不同粒度级别的各种代码元素的数值向量之间的有效相似性比较,可以检测到彼此相似的克隆以及与已知缺陷相似的错误。
基于代码嵌入和相似性检查,SMARTEMBED以统一的方法针对两个任务:克隆检测和错误检测。
- 对于克隆检测,SMARTEMBED 可以识别类似的智能合约。
- 对于错误检测,基于错误数据库,SMARTEMBED可以检测以太坊区块链中现有合约中的错误或由Solidity Developer提供的与数据库中任何已知错误类似的智能合约中的错误。方法包含两个阶段:模型训练阶段和预测阶段
2.2 模型训练
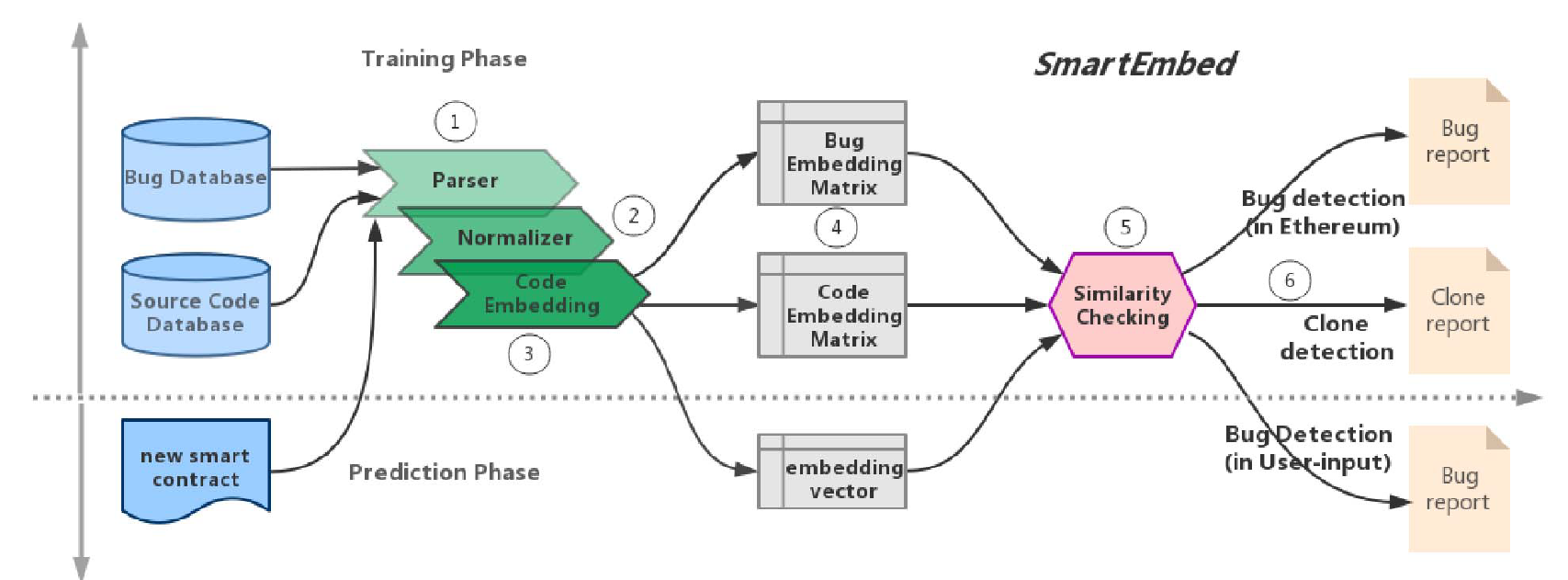
在模型训练阶段,主要有4个步骤:
- 步骤一:为智能合约源代码构建了自定义的Solidity解析器。
解析器为我们收集的数据集中的每个智能合约生成一个抽象语法树(abstract syntax tree,AST),然后根据树节点的类型将解析树序列化为标记流。 - 步骤二:规范化器(the normalizer)重新组合标记流(stream of tokens),以消除智能合约之间的不必要差异(例如,停用词,常量或文字的值)。
- 步骤三:将输出标记流(The output token streams)嵌入代码的学习模块,并将每个代码片段嵌入到固定维度的数值向量(numerical vector)中。
- 步骤四:在代码嵌入学习步骤之后,将所有源代码编码到源代码嵌入矩阵中(source code embedding matrix);同时,我们收集的所有错误陈述都被编码到bug嵌入矩阵(the bug embedding matrix)中。
2.3 模型预测
在预测阶段,通过执行步骤1,2,3并利用学习的嵌入矩阵(embedding vectors),将任何给定的新智能合约转换为嵌入向量。在给定合同的嵌入和收集的数据库中的嵌入之间执行相似性比较(步骤5)。相似阈值用于控制给定合同中的代码片段是否将被视为代码克隆或与克隆相关的错误(步骤5)。
2.4 具体步骤
2.4.1 Solidity解析器(Parsing)
SMARTEMBED使用ANTLR3和自定义Solidity 程序为每个智能合约生成AST。list1显示了一个智能合约的简单示例在Solidity中定义,取决于树的类型节点,对于合同级别,AST的序列化方式不同和语句级程序元素来捕获结构焦点要素及其周围的信息。
1 | |
Listing 1. 一个Solidity程序
2.4.1.1 合同级别解析(Contract Level Parsing)
通过有序遍历从ASTS中提取所有终端标记,示例代码的合同级别解析结果如下所示:
1 | |
2.4.1.2 语句级解析(Statement Level Parsing)
对于语句解析(statement parsing),更多的结构信息(containment and neighbouring))以及一些语义信息(data-flow)被添加到序列中。语句级解析结果如下。
1 | |
2.4.2 规范化(Normalization)
SMARTEMBED规范化分析序列以删除一些与语义无关的信息;所有简单变量,非必要的标点符号和不同类型的常量都将被替换或删除。以下代码段示例了此步骤的操作:
1 | |
2.4.3 代码嵌入学习(Code Embedding Learning)
SMARTEMBED通过改编自单词嵌入的技术,将代码元素和bug模式(包括它们的词汇,句法和一些语义信息)嵌入到数字矢量中。选择Fasttext 作为代码嵌入算法,因为它的性能与传统word2vec相同或更好。
2.4.3.1 标记嵌入(Token Embedding:):
将标准化工具为Solidity合同生成的具有结构信息的标准化标记流用作训练语料库(training corpus)。将Fasttext算法改编为训练代码嵌入模型,训练后,训练语料库中的每个标记(包括代表结构信息的标记)都将映射到具有固定维向量的实际值中。
2.4.3.2 更高层次的嵌入(Higher Level Embedding)
基于每个标记的基本矢量表示,将更高级别代码片段(例如,语句,函数,子合同和合同)的代码嵌入组合在一起。更具体地说,将特定代码片段(a particular code fragment)的代码嵌入定义为其所有组成标记(constituent tokens)的嵌入之和。
2.4.4 嵌入矩阵(Embedding Matrices)
通过将各个向量堆叠在一起,获得用于克隆检测的源代码嵌入矩阵$ C^{c×d} B^{b×d}$。
源代码嵌入矩阵(Source Code Embedding Matrix) $ C^{c×d}$
- 第一个维度c是合同总数;
- 第二维d是我们先前设置的代码嵌入大小。
- 第i个元素Ci(i = 1,2,…,c)是第i个合约的向量表示
Bug声明嵌入矩阵(Bug Statement Embedding Matrix)$ B^{b×d}$
- 第一维b对应于我们的错误数据库中的错误语句总数,并且矩阵的每一行,即Bi(i = 1,2,…,b)表示针对特定错误语句嵌入的代码。
2.4.5 相似性检查(Similarity Checking:)
定义了一个相似性度量,用于克隆检测和错误检测的下游任务。定义:假设C1和C2是两个代码片段,而e1和e2是它们相应的代码嵌入。定义两个代码段之间的语义距离以及相似性,如下所示:

给定任意两个代码片段Ci和Cj,如果它们的相似性得分超过特定的相似性阈值δ,则将Ci和Cj视为一个克隆对。
2.4.6 克隆检测和错误检测
克隆检测和Bug检测任务都可以视为查找“相似”代码的问题的变体,具体取决于相似性的定义。
- 对于克隆检测,测量智能合约对之间的相似性,如果相似性得分超过克隆的预定义阈值,则将它们识别为克隆。
- 对于Bug检测,在给定的合同中搜索与已知错误相似的代码片段,而不是预先定义的错误阈值。
三、实验评估
将SMARTEMBED实施为独立的Web服务,以帮助Solidity开发人员检查其智能合约。
3.1 数据采集(Data Collection)
我们使用EtherScan收集了22,275份经过验证的Solidity智能合约,该合约是Ethereum的区块浏览器和分析平台。这些合同包含135,239个分包合同,631,261个函数,大约200万份报表和700万行代码。同时,收集了22个著名的易受攻击的智能合约,并在合约中查明了37条错误语句,这些语句用作SMARTEMBED的错误数据库。
3.2 后端模型(Backend Model.)
收集到的合同源代码被输入描述方法的工作流中,输出是代码嵌入,它们被用作相似性检查的后端模型。
我们将SMARTEMBED与两个专用于克隆检测(扩展为Solidity的DECKARD [9])和错误检测(SmartCheck [3])的著名工具进行了比较。
3.3 前端用户界面(Frontend User Interface.)。
在用户界面上,SMARTEMBED提供了一个输入框,供Solidity开发人员提交其源代码。在Solidity开发人员将其源代码提交给服务器后,将对源代码进行解析和规范化,然后通过我们的后端模型将合同和每个语句转换为向量,以进行相似性检查。输出分为两个单独的结果选项卡。
初始化Web工具

对于克隆检测结果选项卡,SMARTEMBED返回我们代码库中前5名最相似的克隆合同以及相似性得分,并链接到它们在EtherScan中的位置。
将智能合约粘贴到文本区域,然后单击“summit”。

对于Bug检测结果,SMARTEMBED突出显示提交的源代码中的错误行,并将错误类型报告给开发人员。
bug检测结果将显示如下。

3.4 实验总结
对于克隆检测,针对22,725个智能合约源代码运行了DECKARD和SMARTEMBED,实验结果表明,两种工具都将大约660万行代码识别为代码克隆,而总行数仅为730万,这意味着克隆的可靠性代码约为90%,远高于传统软件。
对于漏洞检测,SMARTEMBED可以更有效,更准确地识别以太坊区块链中与克隆相关的漏洞。当相似度阈值设置为0.95时,SMARTEMBED工具会报告202个与克隆相关的错误,手动验证这些候选错误,其中194个被标记为真实错误,而SmartCheck只能检测其中的117个。
四、总结评论
本文介绍了SMARTEMBED,这是一种用于准确高效地检测智能合约中的代码克隆和错误的Web服务工具,能够极大地节省了效率。它开发了一种用于Solidity代码中的代码嵌入技术,并利用相似性检查来搜索满足某些阈值的“相似”代码。该方法针对从以太坊区块链收集的合同和错误数据是自动化的。
这是一种轻量级的智能合约漏洞检测工具,不过很依赖于所存储的bug数据库,只能找到已知的合约漏洞,不能自主发现最新的漏洞,这点算是不足。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!