Order Matters: Semantic-Aware Neural Networks for Binary Code Similarity Detection
Order Matters: Semantic-Aware Neural Networks for Binary Code Similarity Detection
论文题目:(2020-AAAI)Order Matters: Semantic-Aware Neural Networks for Binary Code Similarity Detection 「用于二进制代码相似性检测的语义感知神经网络」
论文引用:Yu Z, Cao R, Tang Q, et al. Order Matters: Semantic-Aware Neural Networks for Binary Code Similarity Detection[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2020, 34(01): 1145-1152.
公开的API:https://github.com/binaryai/sdk
一、主要内容
本文介绍了一个使用神经网络进行二进制代码相似度检测的工作。首先,对于二进制代码上基本块+控制流图的表示方式,作者首先提出了一个语义表示 + 结构表示(semantic-aware modeling, structural-aware modeling)的表示方法,对每一个基本块将其看成一个sentence,使用BERT对其训练以获得其向量表示,之后使用MPNN对整个CFG进行向量表示,并提出了四个task(masked language model task (MLM),adjacency node prediction task (ANP),Block inside graph task (BIG),graph classification task (GC))对表示进一步优化。另外,作者还提出了CFG中控制结构的重要性,并使用CNN对CFG的邻接矩阵进行学习,并且这种节点的顺序信息也在实验中起到了很好的效果。
二、设计实现
二进制代码检测是在不获取源代码的情况下,得到二进制函数之间的相似性,这是计算机安全方面的一个重要任务。传统的方法通常使用图匹配算法(graph matching algorithms),这往往会非常的慢而且准确率不高。
目前基于神经网络的方法获得很大的提升,二进制函数首先表示成控制流图(CFG),然后通过图神经网络(GNN)来获取相应的编码;尽管这些方法高效且有用,但不能充分的捕捉二进制代码的语义信息。
正如图一所示,第一,每个手工选择特征的block代表了一个低维的嵌入,这将导致大量语义信息的丢失。第二,节点的顺序在二进制函数中扮演了很重要的角色, 然而先前的研究方法没有涉及到提取它。
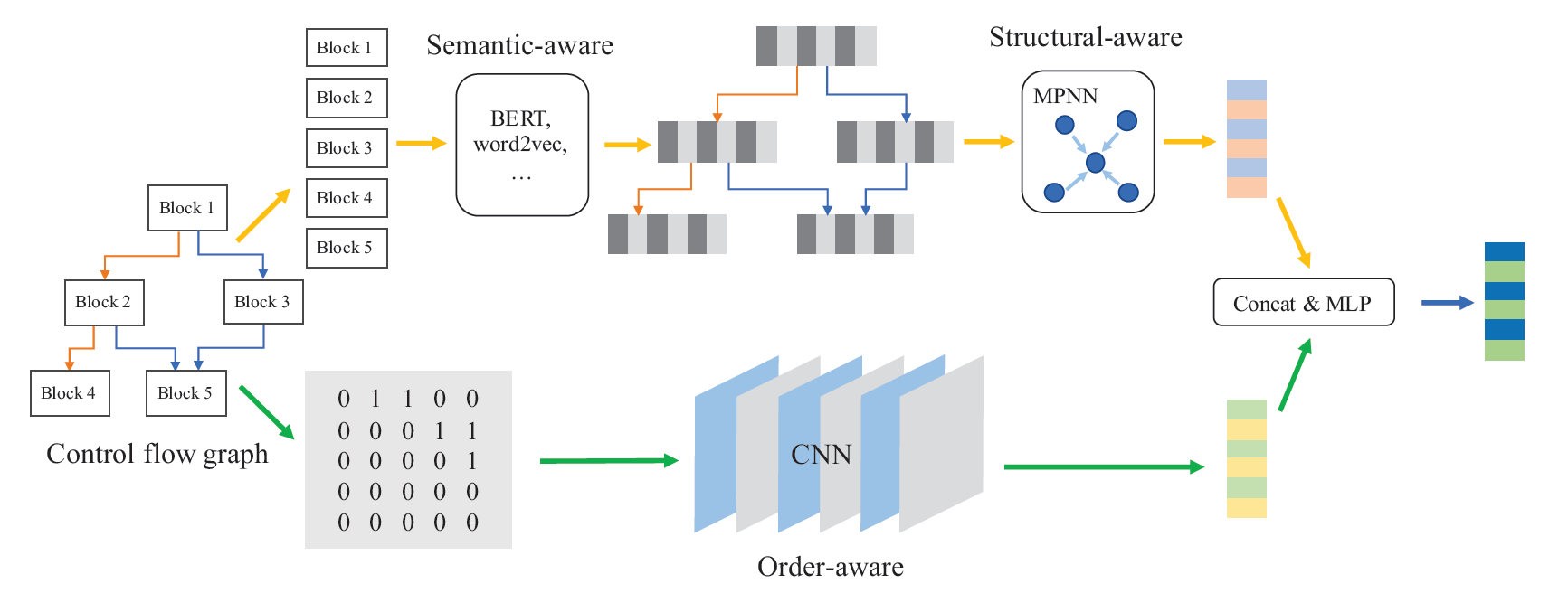
为了解决这两个问题,作者提出了一个包含三个部分的框架,语义感知模型(semantic-aware modeling),结构感知模型(structural-aware modeling),顺序感知模型(order-aware modeling)。
语义感知模型
作者使用了自然语言处理模型在二进制代码中提取语义信息。在CFG块中的符号被视为单词,整个块被视为句子。在先前的工作中,(2019的Massarelli)使用了word2vec模型来训练块中的符号嵌入,然后使用attation机制来获得块嵌入。(2018 zuo)在神经机器翻译中借了一个idea在跨平台的二进制代码上学习语义关系。在这篇文章中,作者使用了Bert(devlin 2018)来预训练符号和块。
结构感知模型
使用MPNN(gilmer在17年提出)和GRU(cho在14年提出)更新功能结合使用。(xu在18年提出)已经证明了图神经网络可以像Weisfeiler-Lehman test (Weisfeiler and Lehman 1968)一样具有辨别能力。发现在每一步都使用GRU比仅仅使用tanh函数能存储更多的信息。
顺序感知模型
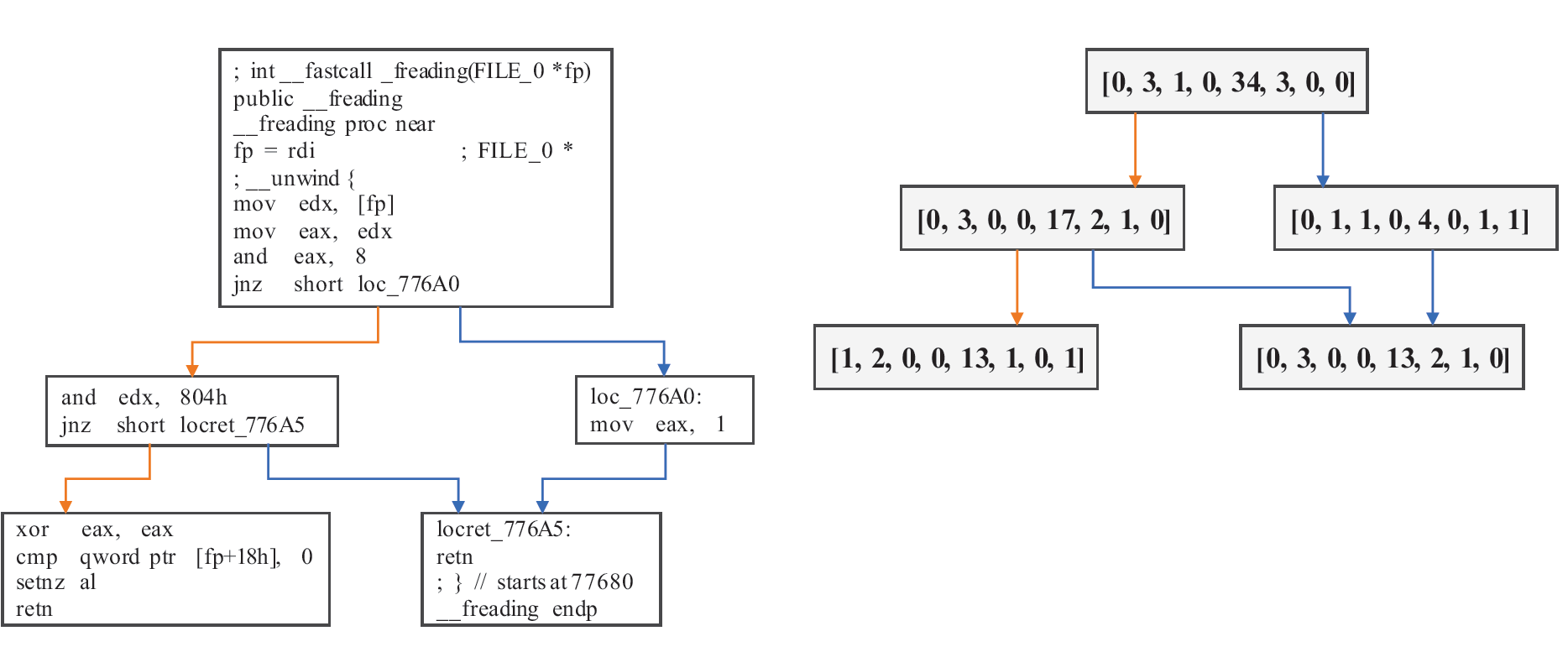
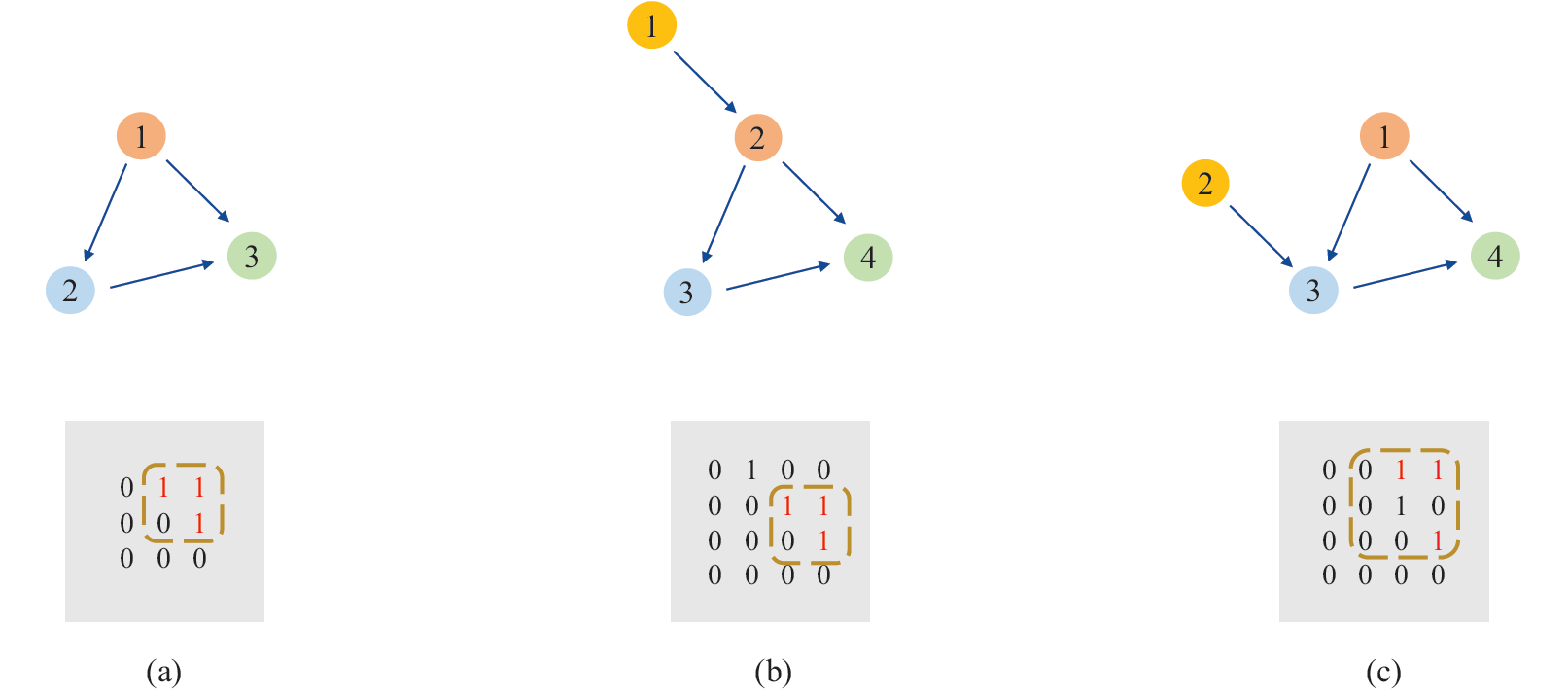
试图去设计一个体系来提取控制流程图的节点顺序信息。图二显示了一个函数的两个控制流程图和它们相应的邻接矩阵在x86和arm平台上.
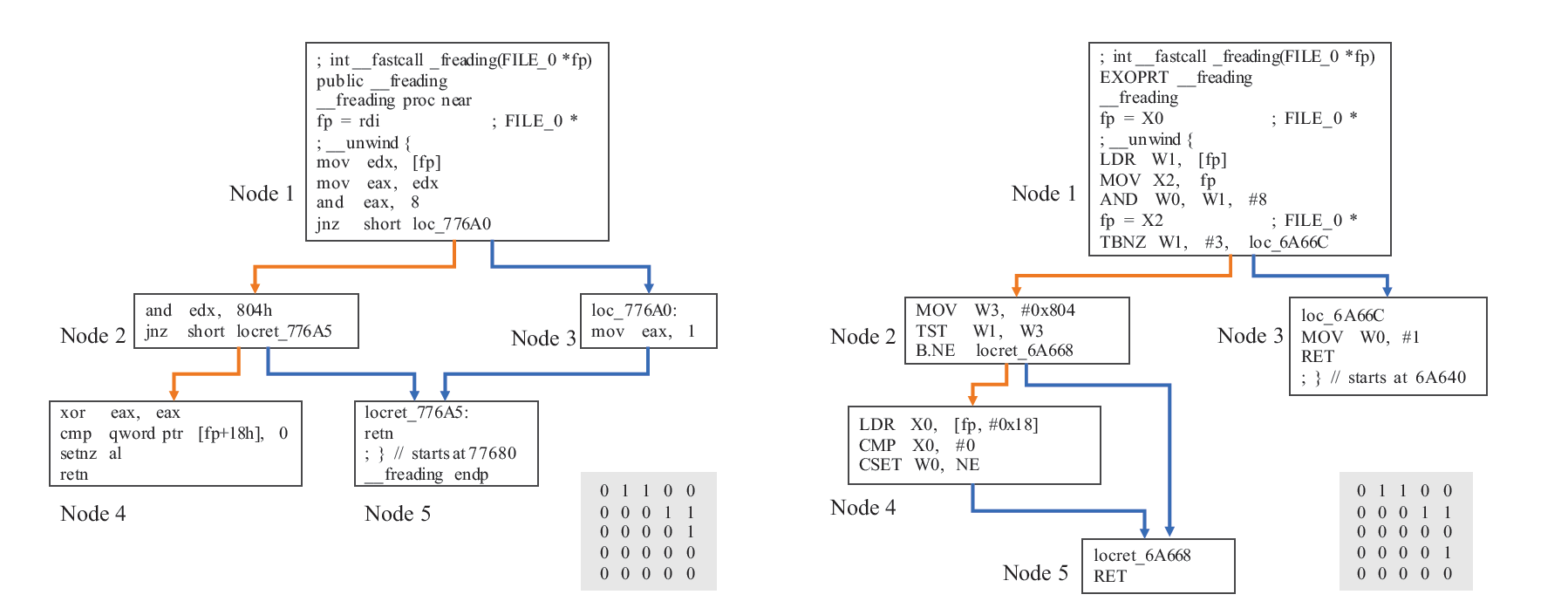
两个不同架构下同一函数编译出的控制流程图和它们的邻接矩阵。这两个CFG有相似的节点顺序。举个例子,节点一与2,3相连,节点2与4,5相连。它们的邻接矩阵非常相似,在研究了很多跨平台的函数对之后,我们发现节点顺序的许多变化非常小。
基于此观察,我们提出一种简单的方法来捕获节点顺序信息。在邻接矩阵上使用CNN,我们发现3层的CNN表现最好,并且进一步探索了如resnet之类的其他模型,并讨论了CNN可以从邻接矩阵中学到什么。
Model
模型的输入是二进制代码函数的CFG,其中每个块都是中间表示的词序列。 我们的模型的整体结构如图3所示。在语义感知组件上,该模型以CFG作为输入,并使用BERT来预训练词嵌入和块嵌入。 在结构感知组件上,我们将MPNN与GRU更新功能配合使用计算图的语义和结构嵌入 。 在顺序感知组件上,该模型以CFG的邻接矩阵为输入,并采用CNN来计算图的顺序嵌入。 最后,我们将它们连接起来,并使用MLP层来计算图形嵌入 。
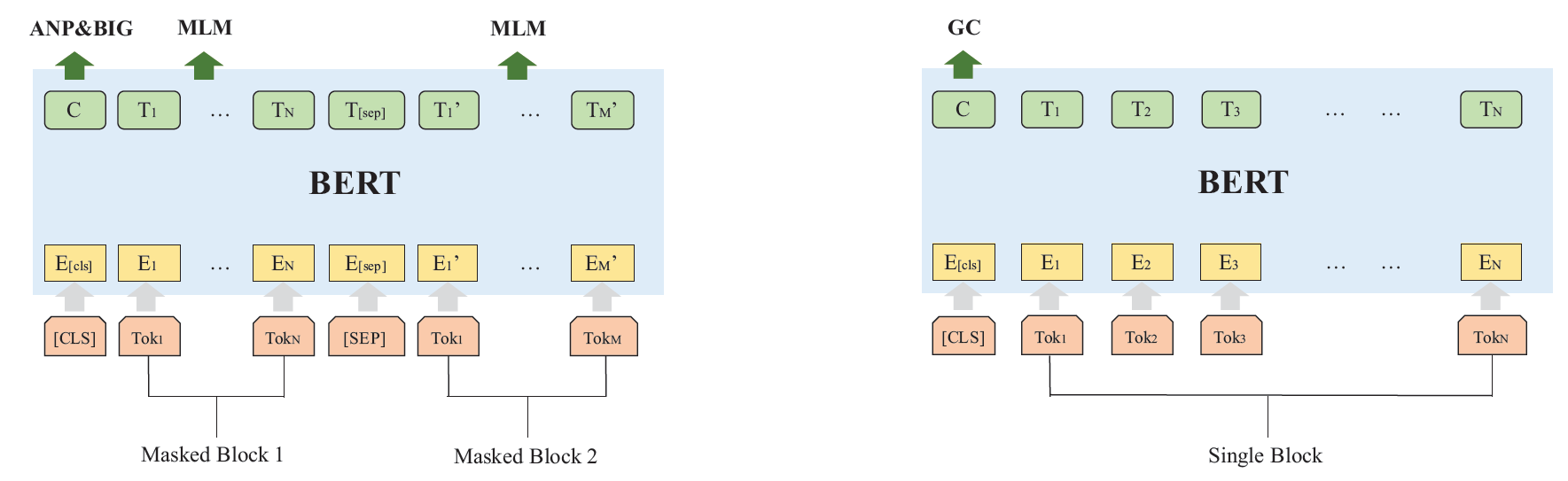
语义感知模型
- MLM是词级别的任务,它在输入层上屏蔽词并在输出层上对其进行预测
- 在ANP任务中,我们提取图形上的所有相邻块,并在同一图形中随机采样几个块以预测两个块是否相邻。(类似原BERT论文中的NSP任务)
- BIG的任务与ANP相似,区别在于对不同块对进行采样的方式。BIG任务试图使模型判断同一图上是否存在两个节点。 我们在/不在同一图中随机采样块对,并在BIG任务中预测它们。该任务有助于模型理解块与图之间的关系
- GC使模型可以对不同平台,不同体系结构或不同优化选项中的块进行分类。
结构感知模型
- 在语义感知模型中获取块嵌入后,使用MPNN计算每个CFG的图语义和结构嵌入;
- 在消息函数M上使用MLP;
- 在更新函数U上使用GRU来学习时间迭代的顺序信息;
- 使用求和函数,并提取第0步和第T步的图形表示。
顺序感知模型
- Block节点的数量和位置进行了变化,但倒三角的特性仍然存在
- 利用CNN的平移不变性和规模不变性,CNN可能会学习节点顺序的细微变化;
- 当在不同平台上编译相同功能时,节点顺序通常不会发生太大变化。大多数节点顺序更改是添加节点,删除节点或交换多个节点,因此CNN对我们的任务很有用;
- 与传统的图特征提取算法相比,直接在邻接矩阵上使用CNN的速度要快得多
CNN的结构:
- 使用11层的Reset网络;
- 包含3个residual block;
- 所有特征图都是3 * 3;
- 使用全局最大池化层来计算图顺序嵌入;
三、实验评估
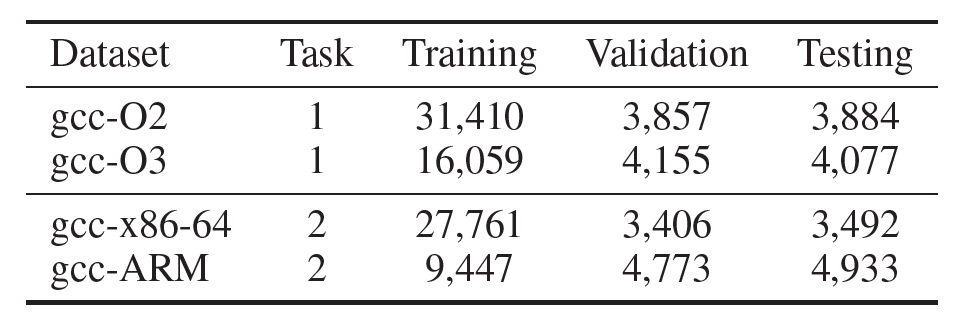
Datasets
任务1是跨平台二进制代码检测任务,在任务1中,包含了O2和O3两种数据集,分别表示在gcc编译器上进行O2和O3两种优化选项的结果。
任务2是图的分类任务,包好了两个在不同平台上编译的代码,在每一个数据集中包含了不同优化选项的数据,期望能够根据图的embedding结果对优化选项结果进行分类。
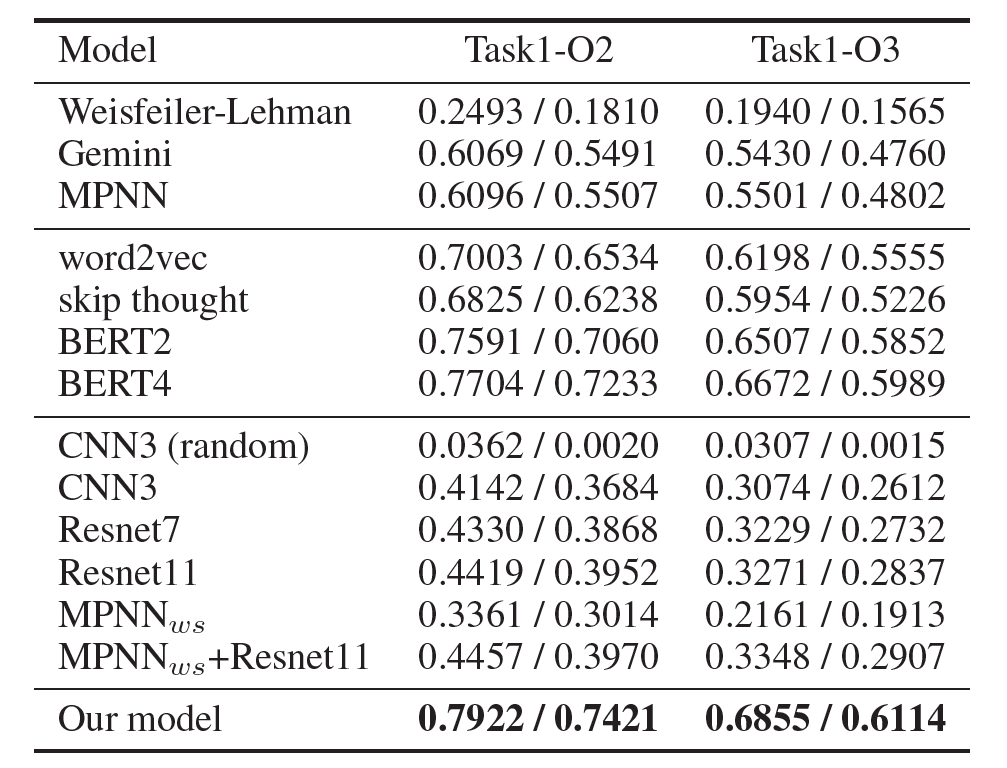
Results
表中第一个分块是整体模型,包括graph kernel,Gemini以及MPNN模型。第二个分块是semantic-aware模块的对比实验,分别使用了word2vec,skip thought,以及BERT,其中BERT2是指原始BERT论文中的两个task(即MLM和ANP),BERT4是指在此基础上加入两个graph-level task(BIG和GC)。第三个分块是对order-aware模块的对比实验,基础CNN模型使用3层CNN以及7、11层的Resnet,CNN_random是对训练集中控制流图的节点顺序随机打乱再进行训练,MPNN_ws是去除控制流图节点中的语义信息(所有block向量设为相同的值)再用MPNN训练。最后是本文的最终模型,即BERT+MPNN+Resnet。
四、评论总结
1、本文使用semantic-aware neural networks来获取捕捉其中的语义信息
2、使用BERT在 one token-level,one block-level, two graph-level 任务上来对二进制代码预训练
3、发现了CFG节点之间的顺序对图的相似性检测也很重要,使用了CNN抽取邻接矩阵(adjacency matrices )的节点顺序信息
主要是对这方面的知识不甚了解,好了很多时间来读。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!