Contractward: Automated vulnerability detection models for ethereum smart contracts
ContractWard:Automated Vulnerability Detection Models for Ethereum Smart Contracts
论文标题:(2020-TNSE) ContractWard- Automated Vulnerability Detection Models for Ethereum Smart Contracts——以太坊智能合约的自动漏洞检测模型
论文引用:Wang W, Song J, Xu G, et al. Contractward: Automated vulnerability detection models for ethereum smart contracts[J]. IEEE Transactions on Network Science and Engineering, 2020.
代码开源:未找到开源代码
主要内容
本文作者提出了ContractWard,其使用机器学习技术检测智能合约中的漏洞。首先,从智能合约的简化操作代码(simplified operation codes)中提取二元语法(bigram)特征;然后采用五种机器学习算法和两种采样算法来构建模型。
通过以太坊上运行的49502个实际运行智能合约来对ContractWard进行了评估,结果表明: 当使用XGBoost训练模型和使用SMOTETomek平衡训练集时,预测的ContractWard的Micro-F1和Macro-F1超过96%,每个智能合约的平均检测时间为4秒。
引入
Oyente ,Mythril和Securify这几种现有的工具很耗时,可能不适合批量漏洞检测,因为这些工具主要采用符号执行或符号分析,这些符号执行或符号分析需要探索合同中的所有可执行路径或分析合同的依赖关系图(dependency graphs)。
ContractWard是基于机器学习技术,目的是在确保的检测准确性的前提下提高智能合约中漏洞检测的效率;它能够根据从训练样本中学到的漏洞来快速有效地检测漏洞。主要分三步构建ContractWard:
- 在2018年11月使用以Solidity语言编写的源代码收集了49502个经过验证的以太坊智能合约,将合同标记为Oyente的六种漏洞。
- 从操作码(operation codes,opcodes)中提取描述合同静态特征的典型特征。源代码被编译为字节码(bytecodes),字节码被转换为操作码。
- 用机器学习算法来检测智能合约中的漏洞
- 采用两种采样算法,即综合少数群体过采样技术(Synthetic Minority Oversampling Technique,SMOTE)和SMOTETomek ,以平衡训练数据集,因为数据是类别不平衡(class-imbalance)的。
- 检测测试智能合约是否易受攻击,采用五种机器学习算法:
- 极限梯度提升(eXtreme Gradient Boosting,XGBoost)
- 自适应提升(adaptive boosting,AdaBoost)
- 随机森林(Random Forest,RF)
- 支持向量机(Support Vector Machine,SVM)
- k-最近邻(k-Nearest Neighbor,KNN)
主要贡献如下:
- 提出ContractWard的系统,用于通过机器学习算法对以太坊智能合约进行大规模,自动的漏洞检测。与现有的工作主要依靠符号执行不同,ContractWard从训练样本中学习易受攻击合同的模式以进行检测。
- 为了更好地描述智能合约的特征,从以太坊官方网站收集了49502个实际的智能合约。进一步从简化的操作代码中提取1619维双峰特征(1619 dimensional bigram features),以构建特征空间。
- ContractWard快速、有效和自动地检测智能合约的六个漏洞。在真实合同上运行ContractWard,系统的(predictive recall)和准确性达到96%以上。此外,每个合约的检测时间约为4秒。经实践证明,ContractWard节省时间、且适合批量检测智能合约中的漏洞。
背景介绍
智能合约的字节码和操作代码
在 EVM 上,它使用三个步骤来部署合同:
- 首先,源代码由开发人员用高级语言编写的(例如:Solidity)
- 其次,源代码被编译器编译为字节码(Bytecodes)或EVM 码(EVM code);字节码是由十六进制数字编码的字节数组。
- 字节码通过以太坊客户端(Ethereum client)上载到 EVM。
字节码可以转换为 EVM 指令(instructions)或操作代码(opcodes)。根据以太坊黄皮书,有135个操作指令,具有10个功能:
- 停止和算术操作(stop and arithmetic operations)
- 比较和位逻辑操作(comparison and bit-wise logic operations)
- SHA3操作(SHA3 operations)
- 环境信息操作(environment information operations)
- 块信息操作(block information operations)
- 堆栈、内存、存储和流操作(stack, memory, storage and flow operations)
- 推送操作(push operations)
- 交换操作(exchange operations)
- 日志记录操作(logging operations)
- 系统操作(system operations)
目前,某些指令未定义,它们将仅用于将来的扩展。由于源代码中定义了大量人为变量(man-made variables),因此使用源代码分析智能合约可能不合适。
- 例如,有两个名为 A 和 B 的合同,其中合同 A 的函数声明是
function transfer(address _to,uint256 _value),而合同B的函数声明:function transfer(address _receiver; uint256 _token);它们看起来与源代码大不相同,但在操作代码中相似。
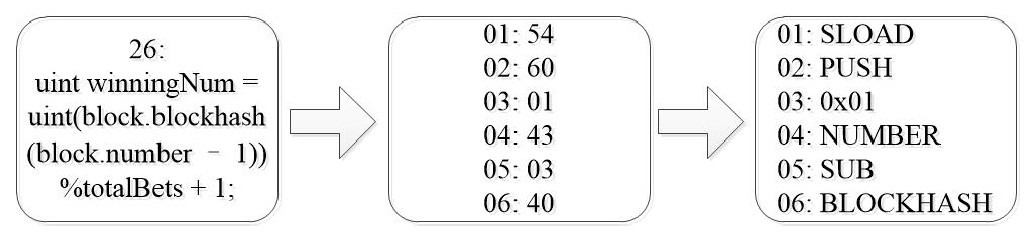
显然,使用操作代码分析智能合约会更容易。下图说明了源代码、字节码和操作码之间的关系
智能合约中的六种安全漏洞
整数溢出和整数下溢漏洞
Integer Overflow and Integer Underflow Vulnerabilities
计算机语言中的整数类型值具有最大值(max)和最小数(min)范围,整数类型在区块链上是无符号(unsigned)的,因此最小值为 0。假设一个无符号整数为 8 位,因此最大值为 。当计算超过最大值或低于最小值时,由于 和
事务序列性依赖 (TOD)
Transaction-Ordering Dependence
在区块链上,智能合约的表现因交易序列而异。不幸的是,这些序列可能被矿工操纵。考虑一个待定事务池(the pending transaction pool,txpool)有两个新事务( 和 ) 和区块链处于状态 ,并且状态 只有在事务 处理时才能转换为状态 。
- 最初, 应在状态 中处理,因此状态从 。
- 但矿工可以按照自己的意愿在之前处理交易,然后状态从 ,而不是从 到。因此,如果此时处理 T,则状态将更改为另一个新状态 。在上述情况下, 在不同的块状态(block states)中处理,并且由预期事务序列的更改而产生漏洞。
调用堆栈深度攻击漏洞
Callstack Depth Attack Vulnerability
在以太坊,在以太坊,合同可以通过某些指令调用其他合同,例如,例如::send()、 :call()、:delegatecall()、.transfer()。但是,如果调用堆栈的深度超过阈值(threshold),除了.transfer(),其他操作不会引发异常而只会返回 false。如果不检查返回值,则调用方(caller)不会意识到调用失败。因此,合同应检查指令的返回值,以确定执行是否按计划进行。
时间戳依赖
Timestamp Dependency
当协定使用块变量(block variables)作为调用条件来执行某些关键操作(例如,sending tokens或作为生成随机数的种子)时,就会发生此漏洞。一些变量在块标题(block header),包括BLOCKHASH, TIMESTAMP, NUMBER, DIFFICULTY,
GASLIMIT和COINBASE,因此,原则上它们能顾被矿工更改。例如,矿工有权在900 秒以内的偏移来设置块的TIMESTAMP 。如果基于块变量传输加密货币,则矿工可以通过篡改这些块变量来利用这些漏洞。
重入漏洞
Reentrancy Vulnerability
重入漏洞是一个臭名昭著的漏洞。智能合约的特性是调用、利用来自外部合约的代码。触发外部合同或向帐户发送加密货币的功能需要提交外部调用(external call)。外部调用可能会被攻击者劫持,以强制合同执行重入代码(reentrant codes),包括回叫(calling back themselves)。因此,相同的代码重复执行,就像编程语言中的间接递归函数调用一样,该漏洞在 2016 年的 DAO 合同中被发现。
设计实现
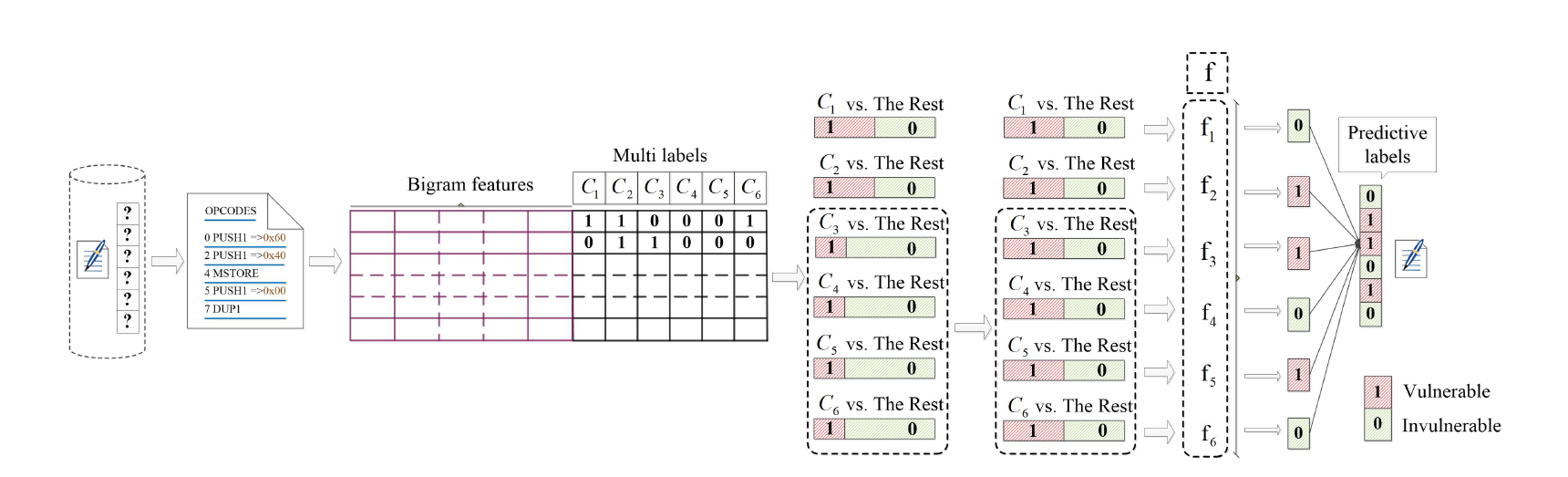
DETECTION MODELS
ContractWard由六个步骤构建。
- 首先,我们从以太坊官方网站收集大量新鲜且经过验证的智能合约
- 源代码转换为操作代码,,然后简化操作代码。
- 从简化的合同操作代码中提取1619 维bigram特征, 并标记具有六种类型的漏洞的合同
- 我们采用One vs. Rest (OvR)算法进行多标签分类,其中 C1 、 C2 、 C3 、 C4 、 C5 和 C6 对应于整数溢出漏洞(Overflow)、整数下溢漏洞(Underflow)、事务排序依赖性( TOD )、调用堆栈深度攻击漏洞( Calltack )、时间戳依赖性(Timestamp)和重入漏洞((Reentrancy)。
- 为了平衡的示例,如 C1 vs 或 C2,我们直接执行分类。对于其余四种类型的漏洞,我们需要使用采样算法在分类前平衡它们,因为类不平衡(class imbalance) 。
- 在用于检测的平衡训练集(the balanced training sets)上构建检测模型
Data Sets, Labels and Feature Space
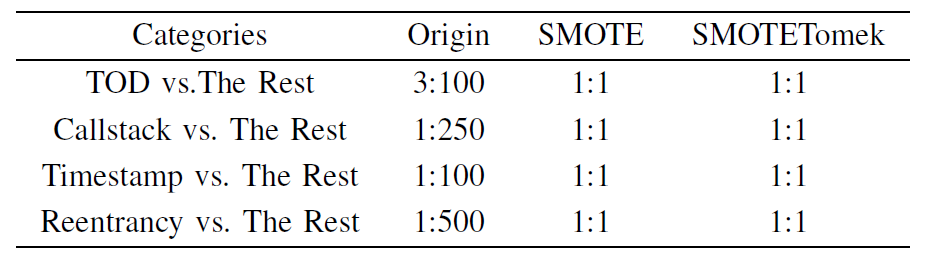
数据集(Data Sets):从以太坊官方网站收集 49502 份包含源代码的智能合约,在 2018 年 9 月之前已验证了智能合约。数据显然可靠、权威和可理解。数据集包含六种类型的漏洞的合同。数据集的说明显示在表1中。对于整数溢出漏洞和整数下溢漏洞,negative(invulnerable,无漏洞)与positive(vulnerable,有漏洞)示例的比率是平衡的。对于其余四种类型的漏洞,阴性与阳性的比率相当不平衡,甚至高达 100:1。阴性示例在多数类中,阳性示例无一例外地在少数类中。通常,如果一个类别与另一个类别的比率超过 5:1,则示例被视为类不平衡(class imbalance)。
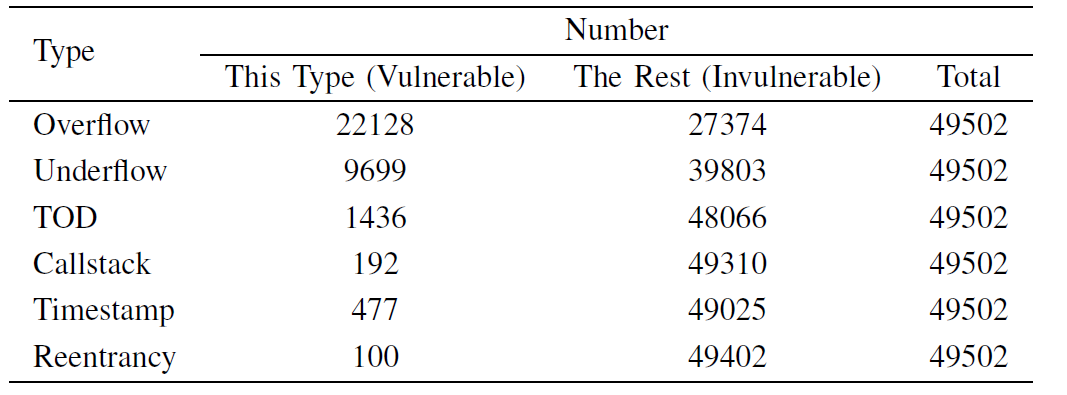
标签(Labels):使用 Oyente来标记所有合同,每份合同都有六个标签。然后,手动检查标签的正确性。在每种类型的漏洞中,标签彼此独立。例如,具有多标签矢量的示例(如 [1 0 1 0 0 0] )表明第一个和第三个漏洞,并且 [0 0 0 0 0 0] 的示例理论上没有漏洞。
Oyente 于 2018 年 7 月更新,包括但不限于 (1) 通过向发送金额添加阈值(例如:sending gas > 2300 和sending tokens > depositing tokens)来减少重入漏洞的误报(false positives);(2)增加 Callstack 漏洞、整数溢出漏洞和整数下溢漏洞检测。(3)将可还原溢出(revertible overflow)视为溢出漏洞的误报。同时,许多论文 使用Oyente特作为比较的基准。故而假设 Oyente 生成的标签是可靠的。
特征空间(Feature Space):采用 n-gram 算法进行特征提取。N-Gram是指连续出现在文本中的n个单词。这是一个概率语言模型(probabilistic language model),鉴于一阶马尔科夫链假说(first-order Markov Chain hypothesis),其中单词只与前面的少数字有关,因此没有必要追溯到智能合约中的第一个操作代码。
- 通过二进制字节大小的滑动窗口(sliding window),操作代码被分割成巨大的 n-grams (massive n-grams)。特别,unigrams、bigrams and trigrams是 n-gram 的示例,其中n分别是 1、2 和 3。
- 换句话说,下一个单词的显示取决于它前面的单词,即bigram;而下一个单词根据前面的两个单词出现,称为trigram。在这项工作中,我们使用bigrams作为特征。根据作者的统计,每份合同的运算码长度平均约为4364个,总共有100多种操作代码。因此,直接使用n-gram算法提取特征可能会导致特征数量过多导致的维数诅咒(the curse of dimensionality)。
为了减少特征的维数,通过取消操作数(dislodging the operands)和将功能上相似的运算码识别为一类来简化操作代码。具体来说就是:
- 可以删除每个推送指令(push instruction)后跟的操作数(operand)。
- 对于块信息说明(block information instructions),简化的 opcode 将作为六个操作代码的替换,这些操作码对 Timestamp 漏洞有同样的影响。因此,在处理之后,只剩下大约50个操作代码。表 II 中介绍了操作代码的简化规则。

如表 III 所示,简化后,从简化的操作代码片段中提取 bigram 功能。每个独特的 bigram 都是一个特征,最终我们提取 1619 维特征,用于识别漏洞。构造一个特征空间 (feature space,FS),其中每个合同都有其相应的特征向量。特征向量中的每个特征值计算为在该维度的bigram与合同中全部bigrams数量的比值。特征空间(FS) 在公式 1 中定义:
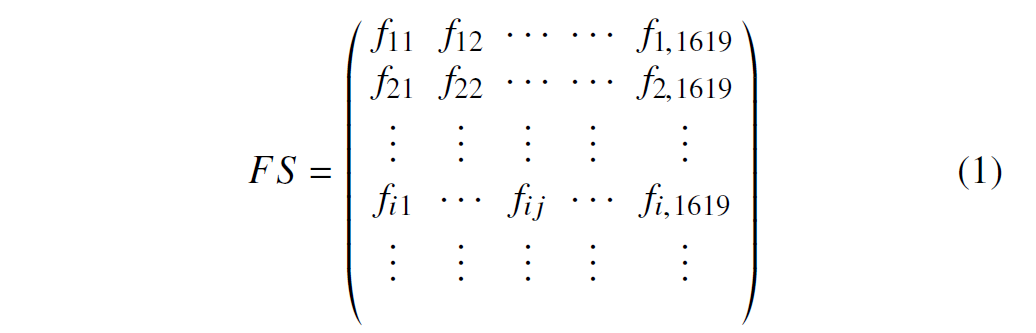
其中 是 合同中 bigram 的特征频率,介于 0 和 1 之间。定义 , 作为 合同中 bigram 发生的数量;并定义 , 作为同一合同中所有bigram发生的总和。
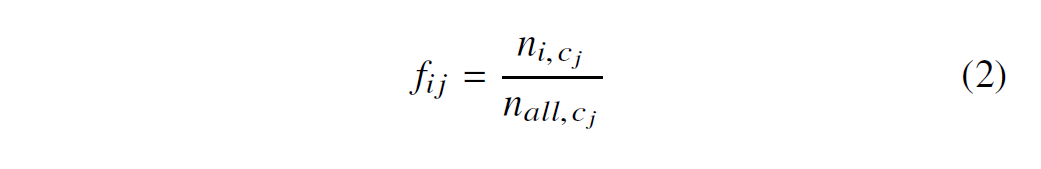
如果合同中其中一个bigram特征未出现,则相应的 为 0。
Training Sets
通常,训练集可以包括从监督分类(supervised classification)中从整个数据集中随机选择的多达 70% 的样本。 然而,在这项工作中,如前所述,训练集不平衡,因为分类类别大致不能平均表示。例如,典型的不平衡数据集(a typical imbalanced data sets)可能包含 97% 阴性的合同示例和 3% 易受攻击的合同示例。如果所有示例都被确定为无漏洞的示例,则预测的准确性为 97%。但是,漏洞检测旨在获取易受攻击合同示例中的高召回率(high recall,R) 和精度 (precision,P)。因此对于不平衡的数据集,只有高精度显然不合适。
召回率 / 查全率 ():指的是被预测为阳性例的占总的阳性例的比重
精准度 / 查准率():指被分类器判定阳性例中的阳性样本的比重
在我们的训练集中,对于某些类型的漏洞,阴性和阳性示例之间的比率相当不平衡,甚至高达 100:1。为了解决这个问题,我们采取措施减少训练集中的分类不平衡影响(the class-imbalance impact)。在细节上,采用
- 合成少数类(Synthetic Minority Oversampling Technique,SMOTE),SMOTE是一种过采样技术(oversamplin technique),在少数类之间插值以产生额外的类。当使用 SMOTE 算法时,可能会生成具有无效信息的样本,从而增加少数类的重叠。
- SMOTE和TomekLinks的组合(SMOTETomek),将少数类的数量扩展至多数类的数量级;SMOTETomek 是一种组合采样技术(combined sampling technique),其使用 SMOTE 的过采样,以及可以删除具有邻域关系(Tomek’s links)的样本的下采样(undersampling)。因此,它可以在采样过程中删除无用的样本。
- 它们都支持多标签重新采样(multilabel resampling)。表四介绍了原始训练集的比例、SMOTE 平衡的训练集后的比例以及 SMOTETomek 平衡的训练集后的比例。我们采用基于平衡数据集的五种监督学习算法,以实现多标签分类。
但是,SMOTETomek 是一种组合采样技术(combined sampling technique)。其使用 SMOTE 的过采样后跟下采样,可以删除具有邻域关系的样本(Tomek 的链接)。因此,它可以在采样过程中删除无用的样本。它们都支持多标签重新采样。表四介绍了原始培训组的比例、与 SMOTE 平衡的训练集的比例以及与 SMOTETomek 平衡的训练集在类别中的比例。我们采用基于平衡数据集的五种监督学习算法,以实现多标签分类。
Classification Algorithms
在训练集中有 和 ,多标签分类任务是通过拆分实现的,即将多标签分类任务划分为多个二进制分类任务。每个二进制分类任务都训练分类器,最后训练了六个分类器。这些二进制分类器的分类结果被集成,以提供多标签分类的最终结果。采用 One vs. Rest (OvR) 策略,这是最经典的拆分策略之一,用于实现多标签分类。
- OvR 的主要思想是训练六个二进制分类器,条件是将一个类别视为阳性类,将其他类别视为阴性类。在训练过程中,如果样本在六个类别中的一些类别中预测为阳性,则相应的标签为 1,这意味着样本在这些类别中具有漏洞。
每个二进制分类任务都采用集成学习算法(Ensemble learning algorithms),以获得比单个学习者更好的泛化性能(generalization performance)。为了便于比较,还采用了单一学习算法(single learning algorithms)。集成学习算法通过组合多个基分类器来完成学习任务,我们在此工作中使用决策树 (Decision Tree,DT)。
集成学习会挑选一些简单的基础模型进行组装,组装这些基础模型的思路主要有 2 种方法:
-
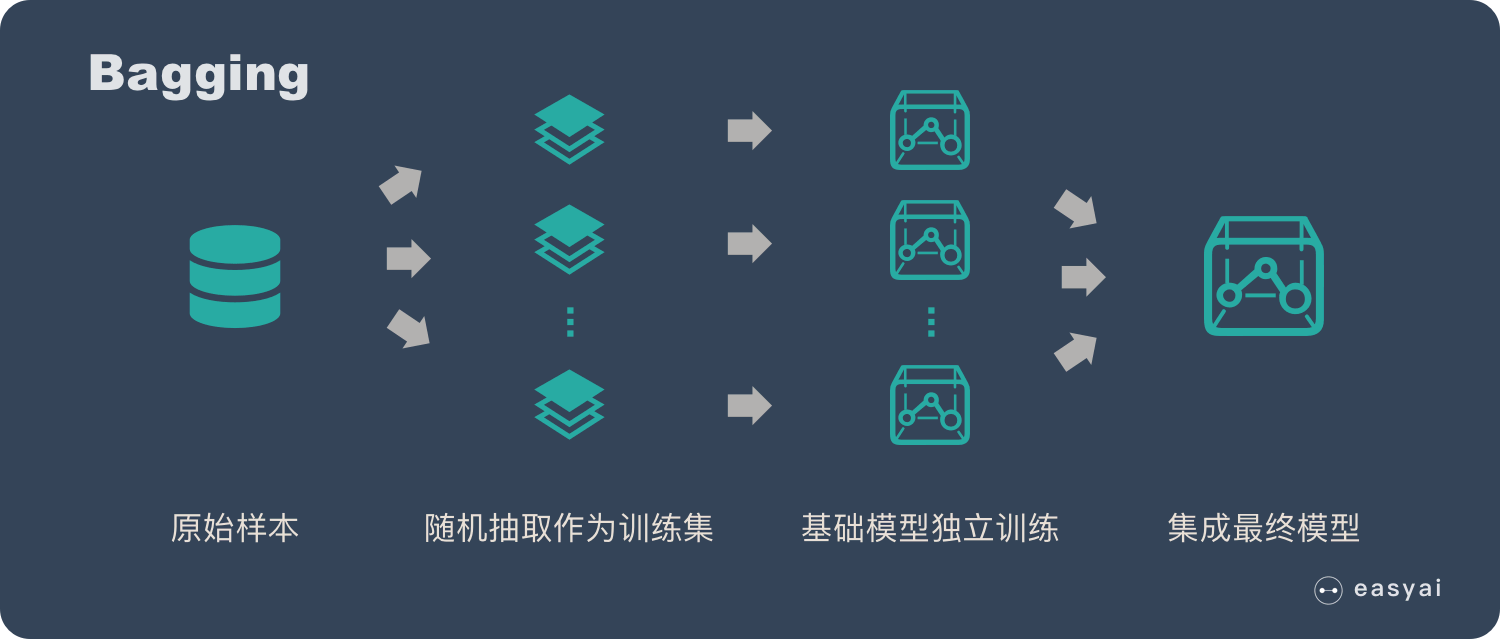
bagging(bootstrap aggregating的缩写,也称作“套袋法”);Bagging 的核心思路是——民主。Bagging 的思路是所有基础模型都一致对待,每个基础模型手里都只有一票。然后使用民主投票的方式得到最终的结果。大部分情况下,经过 bagging 得到的结果方差(variance)更小。
-
boosting:增强。Boosting 的核心思路是——挑选精英。Boosting 和 bagging 最本质的差别在于他对基础模型不是一致对待的,而是经过不停的考验和筛选来挑选出「精英」,然后给精英更多的投票权,表现不好的基础模型则给较少的投票权,然后综合所有人的投票得到最终结果。经过 boosting 得到的结果偏差(bias)更小。
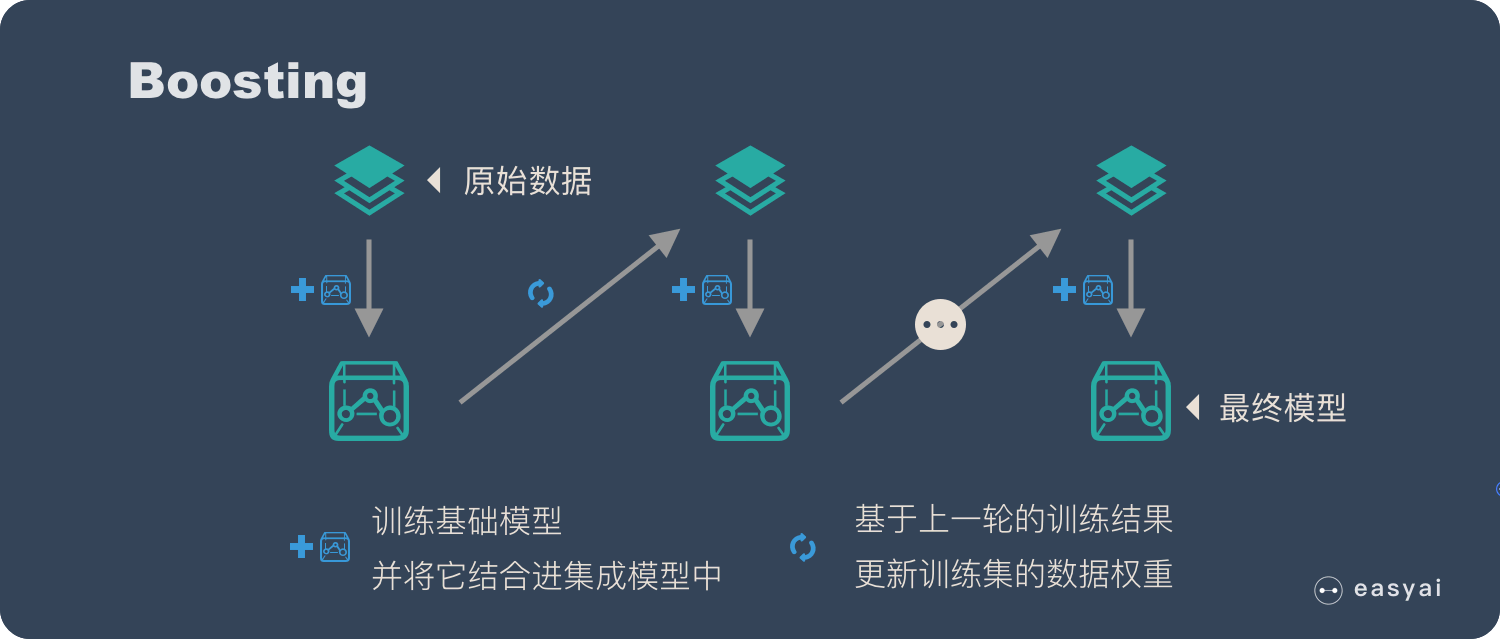
基于训练集的特征空间和标签,采用 eXtreme Gradient Boosting(XGBoost) 来开发 ContractWard 来检测智能合约中的漏洞。我们还采用自适应增强 (adopt Adaptive Boosting,AdaBoost)、随机森林 (Random Forest,RF)、支持矢量机 (Support Vector Machine,SVM) 和 k-最近邻居 (k-Nearest Neighbor,KNN) 进行检测以进行比较。
eXtreme Gradient Boosting (XGBoost): XGBoost 是一种高效的Boosting 算法。为了实现快速拟合,the learner应尽量减少预测值与实际值(例如:残差)之间的差值,并形成正则损耗函数(regularized loss function)。最后,预测是所有learner的总和。XGBoost 利用类似于 RF 的列采样来减少方差。与 AdaBoost 相比,XGBoost 效率很高,因为它支持功能粒度的并行处理,而不是学习粒度(learner granularity)的并行处理。
Adaptive Boosting(AdaBoost):AdaBoost 是增强算法的代表。它开始建立其第一个learner与初始训练集。在重新加权(re-weighting)过程中,它增加了正确分类或预测的样本的权重,同时同时减少错误分类和预测的样本的权重。重新分配样本的权重后,进行下一次训练。重复数次,直到基本学习器的数量达到预先设置的值。最后,通过结合多个弱学习器,可以获得强大的学习器。经过每个弱分类器的训练过程,增加了分类误差率小的弱分类器的权重,使其在最终分类函数中起着更大的决定性作用。相比之下,分类误差率较大的弱分类器的权重减小,在最终分类函数中起着较小的决定性作用。
Random Forest (RF): RF 是Bagging algorithms的扩展变体。训练集由 n 个示例组成,使用随机采样算法替换到从数据集中采样 n 次,反复,直到获得 t 个训练集数。然后分别对 t 基础学习器进行训练。其次,在预测过程中,分类决定取决于多数票。随机属性选择用于训练过程。
支持向量机(SVM):SVM是广泛使用的分类方法。其目标是找到一个超平面(hyper-plane),将样本分割成正样本或负样本,因此这两个类别之间有最大裕量(margin),其中分类器具有高可靠性和良好泛化能力的新样本。
k-最近邻居(KNN):KNN也是非常广泛使用的分类算法。它简单而高效。 给定一个测试样本,根据一些距离测量值找到最接近样本的 k 训练样本,然后根据 k 邻居的信息获得预测。根据多数票,k 样本中最常见的类别标签被选为预测结果。
Model Selection
同一学习算法的超参数的分类结果差异很大。超参数是在学习之前设置其值的参数,而不是可以通过训练获得的参数。因此,在模型选择中,应调整算法的超参数,这通常称为超参数调优。 模型经过预设置的超参数训练,然后通过参数调整获得最优模型的超参数。 此外,决策阈值也根据数据分布进行调整,称为阈值移动。通常,如果预测值超过阈值,默认值为 0.5,则样本被区分为正数,或者相反为负值。通过上述方法,在培训过程中可以很好地避免分类器中过度安装和不拟合的问题。在我们的工作中,我们在培训处理中不采用 n 倍交叉验证(n-fold cross-validation)。
实验评估
在本节中,我们对测试集进行综合实验,以实现三重目标。首先,将采样方法与五个分类器进行比较,以验证采样方法的必要性。其次,F1-score, Micro-F1 值 ,Macro-F1值来衡量分类器的性能。根据评估结果,使用 XGBoost 分类器在合同中使用 SMOTETomek 在平衡训练集上训练。最后对合同的分类结果进行详细分析。
Setup
实验环境:
Test Sets
在实验中,70% 的数据集用作训练数据。如果剩余的 30% 直接用作测试数据,则分类结果在不平衡的测试集上可能不够好。 如前所述,为了平衡测试集,我们采用随机抽样方法从大约 15K 个实际智能合约中选择样本。对于四种类型的漏洞,即 TOD、Callstack 漏洞、Timestamp 漏洞和Reentrancy漏洞,我们从多数类中随机选择样本,并且从多数类中选择的样本数是少数类数的五倍。然后,我们将从多数类和少数类的所有样本中选择的样本组合在一起,以形成最终包含足够样本且没有虚构样本的测试集。
评估指标
F1 score
F1 score是用来评价二元分类器的度量,它的计算方法如下:
- 首先定义以下几个概念
- (True Positive)真阳性:预测为正,实际也为正
- (False Positive)假阳性:预测为正,实际为负
- (False Negative)假阴性:预测与负、实际为正
- (True Negative)真阴性:预测为负、实际也为负
- 通过第一步的统计值计算precision和recall
- 精准度 / 查准率():指被分类器判定阳性例中的阳性样本的比重
- 召回率 / 查全率 ():指的是被预测为阳性例的占总的阳性例的比重
- 准确率():代表分类器对整个样本判断正确的比重
F1是用来衡量二维分类的,Micro-F1 score和Macro-F1 score则是用来衡量多元分类器的性能。
Macro-F1 score
对于一个多分类问题, 、、、、分别是分类的True Positive、False Positive、True Negative、False Negative。
- 分别计算每个类的精度(precision)和召回率(recall)
- 每个类的精度(precision):)
- 每个类的召回率(recall):
- 计算Macro-F1 score的精度和召回率是所有分类的平均值
- Macro-P 精度:$ Precision_{macro}=\frac{1}{n}\sum_{i=i}^{n}precision_i$
- Macro-R 召回:$ Recall_{macro}=\frac{1}{n}\sum_{i=i}^{n}recall_i$
- 套用F1score的计算方法,Macro-F1 score就是:
Micro-F1 score
- 通过的统计值计算的Micro-F1 score的precision和recall
- Micro-P 精度:$ Precision_{micro}=\frac{\sum_{i=i}{n}TP_i}{\sum_{i=i}{n}TP_i+\sum_{i=i}^{n}FP_i}$
- Micro-R 召回:$ Recall_{micro}=\frac{\sum_{i=i}{n}TP_i}{\sum_{i=i}{n}TP_i+\sum_{i=i}^{n}FN_i}$
- Micro-F1 score就是
Sampling Methods
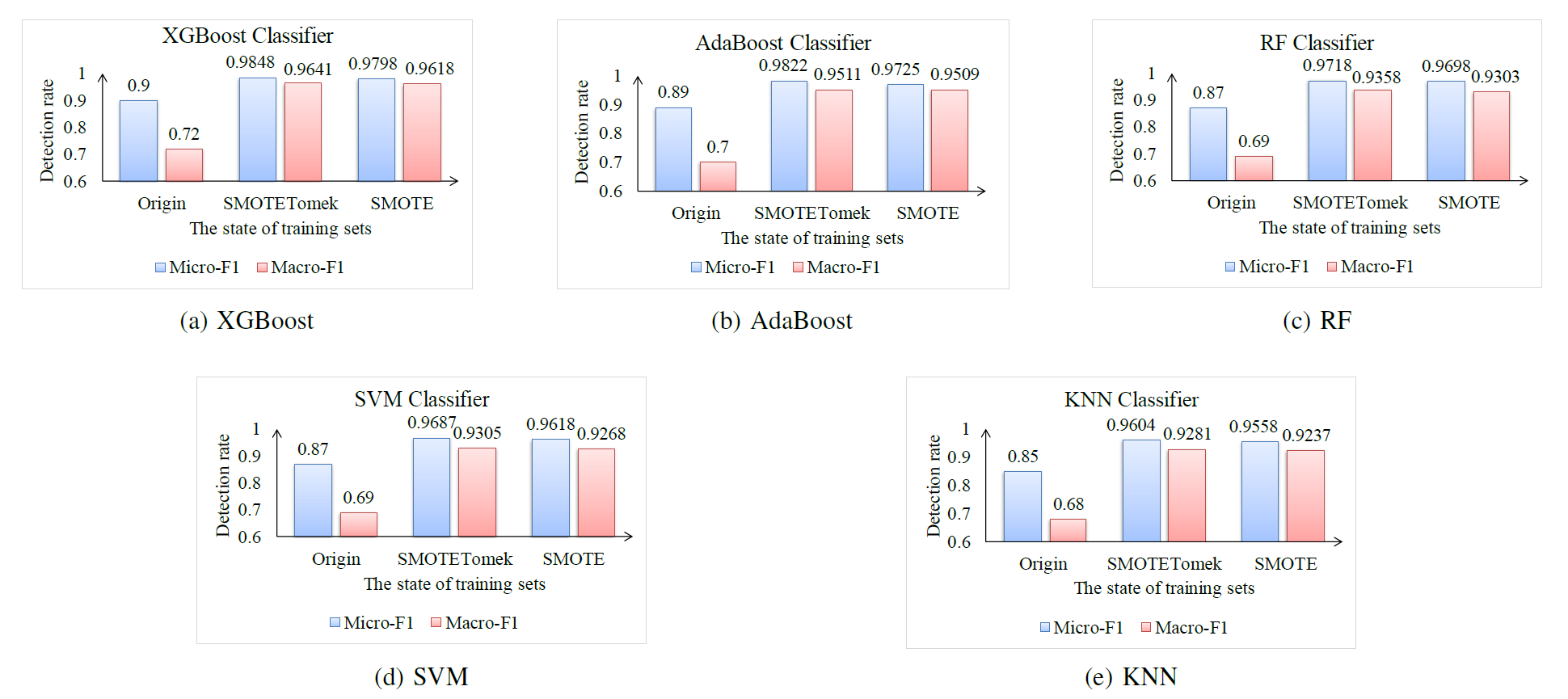
评估我们关于真实世界智能合约的方法。 我们在同一测试集上使用五个分类器,即 XGBoost 分类器、AdaBoost 分类器、RF 分类器、SVM 分类器和 KNN 分类器,每个分类器由三个不同的训练集进行训练,即原始训练集、与 SMOTE 平衡的训练集以及与 SMOTETomek 平衡的训练集,如表四所示。我们选择Micro-F1和Macro-F1 作为分类评估指标。Micro-F1和Macro-F1 是用于评估多标签分类的度量。
- 计算 Micro-F1 时,该值易受具有许多样本的类别的分类结果的影响。
- 计算 Macro-F1 时,无论每个类别中的样本数如何,每个类别的权重都是相等的。
图 4 表明,每个分类器的预测 Micro-F1 和Macro-F1 值与在训练集上训练的与 SMOTE 平衡或与 SMOTETomek 平衡的训练集上的值大于在原始训练集上训练的每个分类器的值。更具体地说,SMOTETomek 在五个分类器中比 SMOTE 效率更高,以平衡数据,而 Micro-F1 和 Macro-F1 在 XGBoost 分类器中都可以达到 96% 以上。因此,SMOTE和SMOTETomek方法可以成功地解决分类器由于类不平衡而导致的泛化能力薄弱的问题。
Classifiers
进行综合实验,目的是比较基于五个多标签分类器的性能,即XGBoost分类器、AdaBoost分类器、RF分类器、SVM 分类器和 KNN 分类器,以及两种采样方法,即 SMOTE 和 SMTOETomek。Micro-F1 和Macro-F1 用于测量分类器的性能。F1-score 是用于评估二进制分类器的度量值,它被定义为召回 (R) 和精度 (P) 的加权平均值(weighted harmonic mean)。
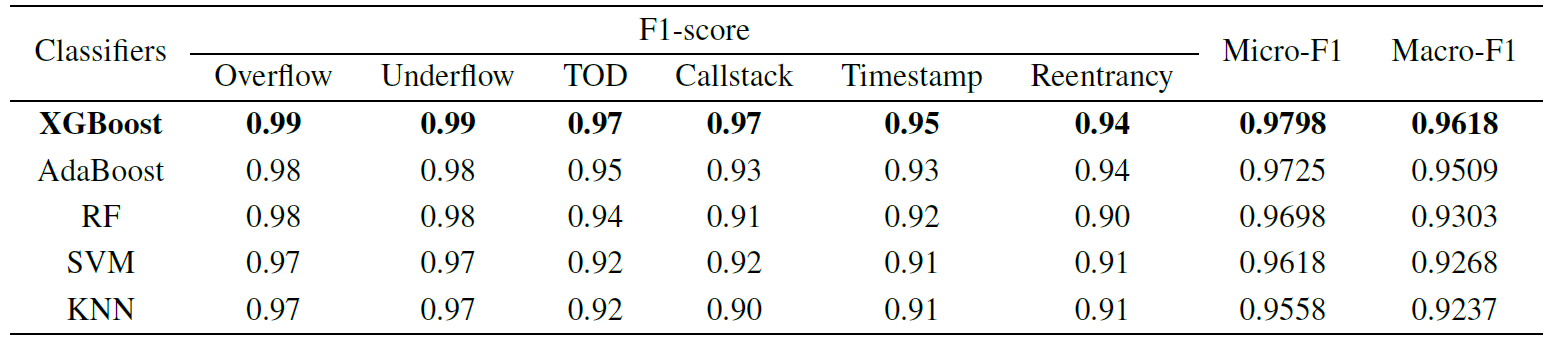
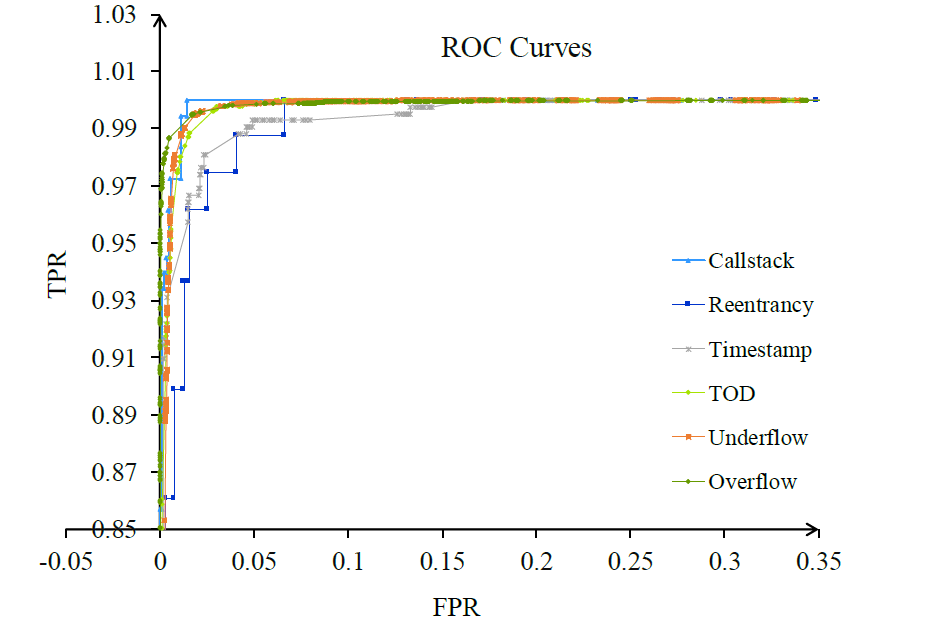
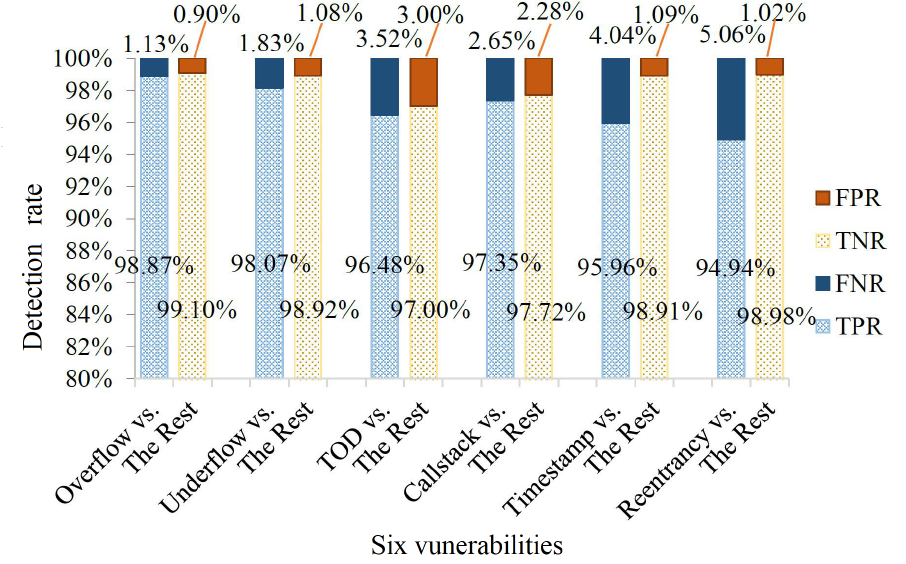
在表 VI 中,可以看到 XGBoost 分类器产生的 F1 得分值比每个二进制分类任务中的 AdaBoost 分类器、RF 分类器、SVM 分类器和 KNN 分类器高。XGBoost多标签分类器的预测微Micro-F1 和Macro-F1 在五个分类器中最高,达到96%以上。
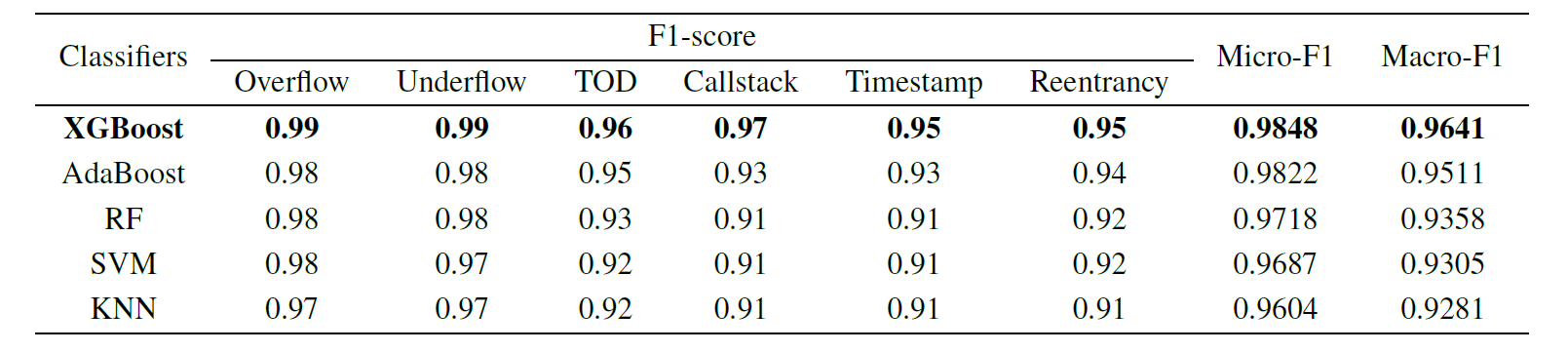
在我们的多标签分类中,集成式学习分类器的表现优于 SVM 和 KNN 分类器。Micro-F1 值大于 Macro-F1 值,因为溢出和下溢漏洞的测试样本数量都很大,并且这两个类别的 F1 得分值很高。比较表六和表七,很明显,XGBoost分类器的性能与SMOTETomek平衡训练,性能好于预期。因此,我们在名为"合同"的模型中将 XGBoost 分类器与 SMOTETomek 方法一起选择。
ContractWard
总结结论
本文选取Oyente作为基准方法,从以往几篇文章来看,这种方法在检测准确度上并不是十分地好,还有更多表现更加优良的方法,如Mythril、Slither等。所以在基准的选取上可能并不是那么得有说服力。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!