Learning features from enhanced function call graphs for Android malware detection
E-FCGS
论文题目: (2020-Neurocomputing) Learning features from enhanced function call graphs for Android malware detection —— 从增强的函数调用图中学习功能以检测Android恶意软件
论文引用:Cai M, Jiang Y, Gao C, et al. Learning features from enhanced function call graphs for Android malware detection[J]. Neurocomputing, 2021, 423: 301-307.
一、主要内容
本文尝试从函数调用中了解应用程序的行为级别特征;这个任务的挑战是双重的。首先,缺少函数属性会妨碍对应用程序行为的理解其次,经典的机器学习算法无法直接处理函数调用的图形表示
为了解决以上两个问题,本文提出两个方法:
- 提出了增强函数调用图(E-FCG)的概念来表征应用程序运行时行为
- 开发基于图卷积网络(GCN)的算法来 获取 E-FCG的矢量表示。
结果表明,通过本文方法学习到的特征可以在各种分类器(例如LR,DT,SVM,KNN,RF,MLP和CNN)上实现高检测性能。
别是,为了利用语法信息,几种方法使用抽象语法树(AST)作为输入,并在各种编程语言中的代码克隆基准方面取得了重大进展。
但是,这些基于AST的方法仍然不能充分利用代码片段的结构信息,尤其是诸如控制流和数据流之类的语义信息。
为了利用控制和数据流信息,在本文中,我们建立了一个称为流增强抽象语法树(FA-AST)的程序的图形表示。
我们通过使用显式控制和数据流边缘扩展原始AST来构造FA-AST。
然后,我们在FA-AST上应用两种不同类型的图神经网络(GNN)来测量代码对的相似性。
就我们而言,我们是第一个将图神经网络应用于代码克隆检测领域的公司。
二、知识背景
FCG
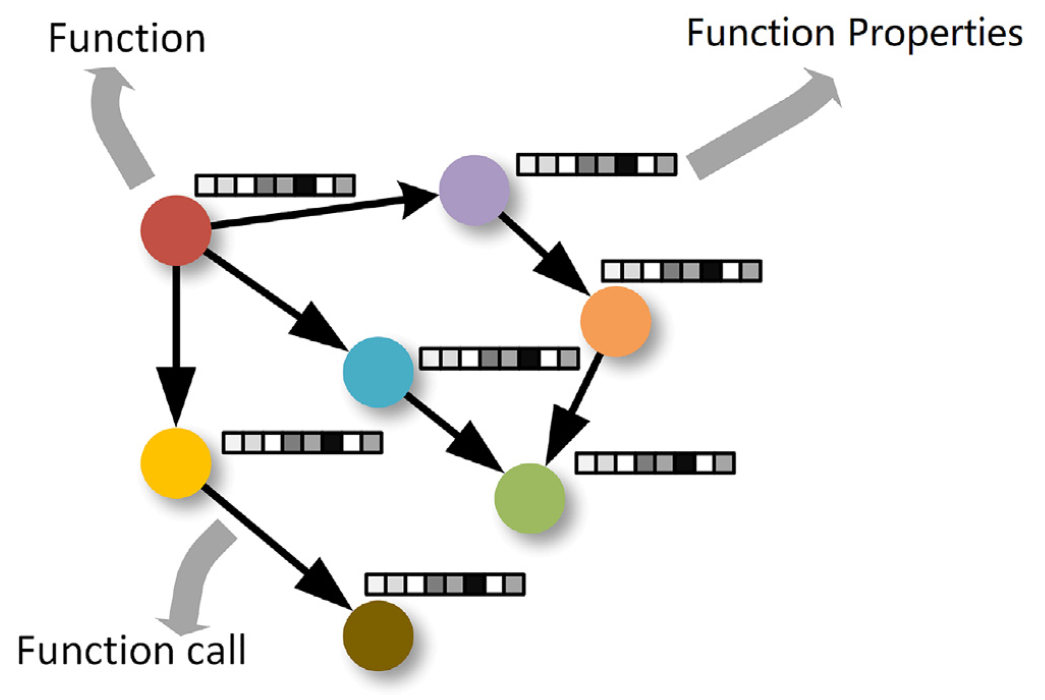
函数调用(Function calls)通常表示为二进制向量或有向图,在FCG(Function Call Graph)中 每个节点代表一个函数,每个边代表一个函数调用。
- 与矢量表示相比,图形表示可提供有关应用程序工作方式的更多信息,从而有助于恶意软件检测。
- 比如:一个FCG中包含onReceive()和startService()之间的一条边,过分析此FCG,认识到该应用程序调用onReceive() 来接收系统广播的BOOT COMPLETE,然后调用startService()来启动用于私有用户数据收集的Service组件,此行为表明该应用程序可能是恶意的
但是,FCG不会告诉有关节点或者函数特征 的信息,例如函数的含义;函数的属性对于恶意软件检测至关重要,
- 例如,在不了解startService()含义的情况下,无法理解应用程序的行为。其次,传统的机器学习算法由于其非欧几里德结构而无法直接处理FCG。
本文使用了 函数embedding 和 基于GCN(图卷积网络)的特征学习解决了以上问题。
embedding
应用程序中的函数类似于文档中的单词,借用词嵌入(word embedding)的思想
- 将函数嵌入到低维向量空间中,该空间中的每个向量都表示一个函数的属性
- 这些属性可以表征该函数的动作,各个函数之间的函数相似性以及与其他函数的关系。
- 通过向FCG中的每个节点分配函数属性来创建增强的FCG(E-FCG)
GCN
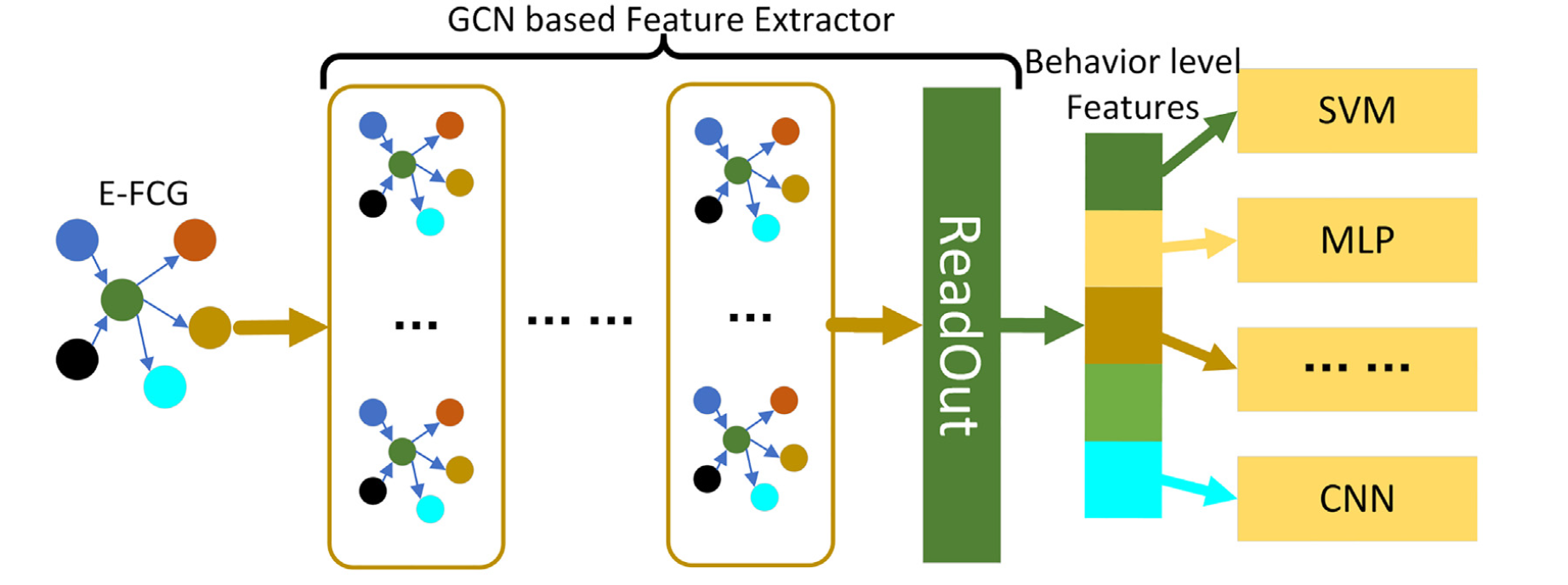
分类器不能直接处理FCG和E-FCG,受图嵌入的启发,本文开发了一种基于GCN的行为级别特征提取算法(BLFE,Behavior Level Features Exaction algorithm)来从E-FCG中学习行为级别特征,通过本文算法获得的有用且密集的矢量表示形式可被各种分类器用于恶意软件检测。
三、设计实现
Construction of E-FCGs
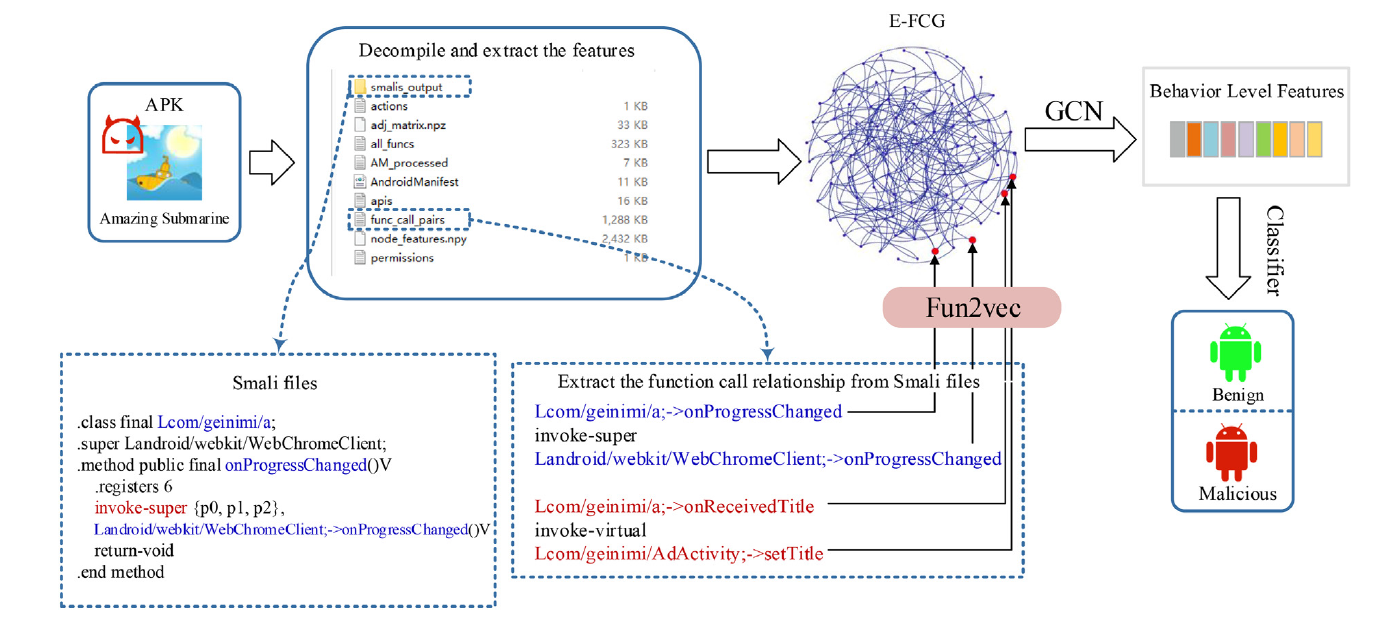
对于Android应用程序,可以通过处理其classes.dex文件来获取函数调用的信息。
意识到程序中的函数类似于文档中的单词,本文使用类似于单词嵌入的方法来获取函数属性,称为函数嵌入,旨在将每个函数转换为密集的矢量表示形式。
函数嵌入的主要过程描述如下:
- 对数据集中的每个应用程序,首先创建一个文件(即函数调用记录)以存储函数调用的顺序
- 然后通过将所有函数调用记录放在一起来建立语料库,遵循CBOW(Continuous Bag Of Words连续词袋)方法,训练一个具有一个隐藏层的全连接神经网络,以将函数转换为N维向量。
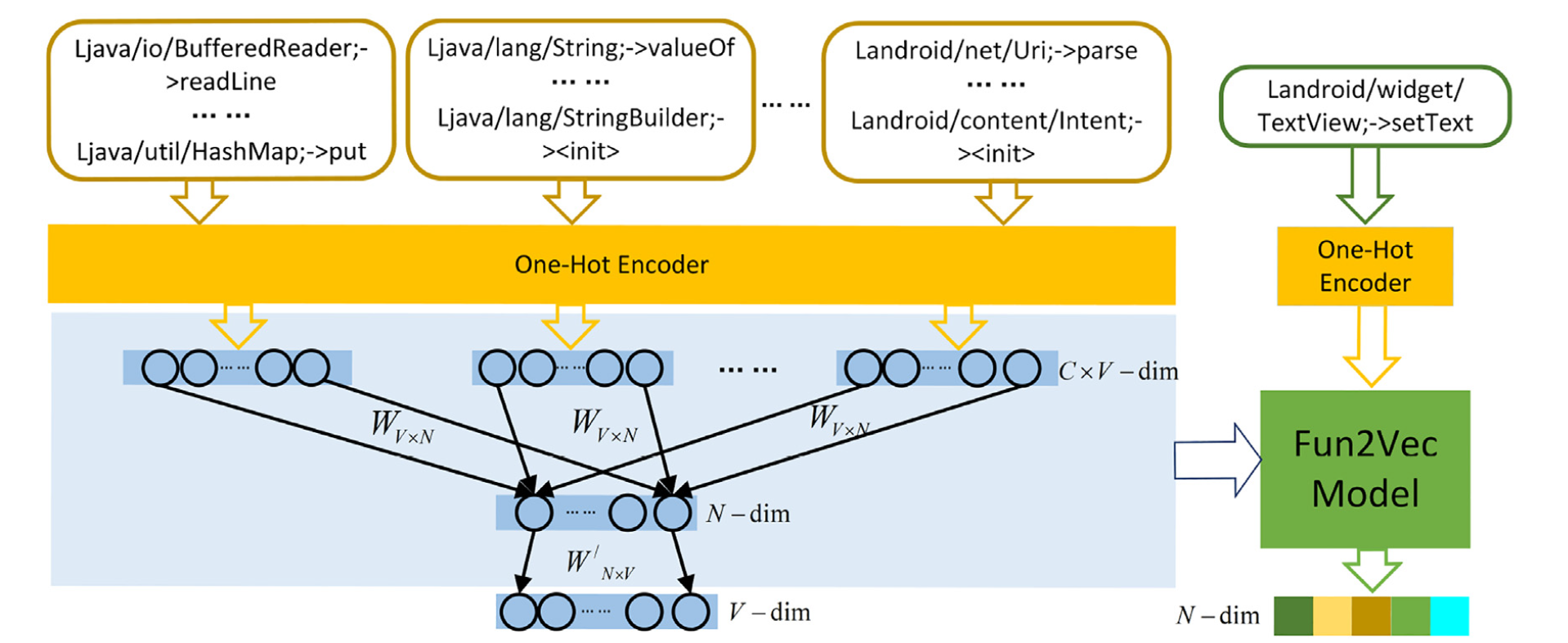
如该图的左侧所示,神经网络一次 处理 C 函数 的 单热编码矢量(one-hot encoded vectors)。
- 所有函数都具有相同的权重,
- 其中 V 是语料库中发生的功能数
- 为了训练该神经网络,反复为其提供从语料库中获得的一系列函数 ,并指导其预测函数。
关于模型训练的更多细节Efficient …word representations in vector space可以在中找到。训练阶段结束时,可以使用权重,得出每个函数的 N维向量 表示形式。
通过函数嵌入,可以通过将向量表示分配给FCG中的每个节点来构造增强的FCG(E-FCG)
Learning features from E-FCGs
经典分类模型(例如SVM和CNN)无法处理E-FCG,因为E-FCG是非欧几里得(non-Euclidean)的,并且属于图数据的类别
为了解决这个问题,建议使用GCN来向E-FCG学习功能。GCN可以直接在图形上操作并利用其结构信息
给定E-FCG,GCN的输入:
- 特征矩阵X,其中每一行是节点的矢量表示(即特征)
- 表示图结构的邻接矩阵A
在每一层,使用传播规则对要素进行汇总,以形成下一层的要素。因此,每个隐藏层 l,可以表示为:
其中有$H^0 = X $
这样,每个连续层的特征变得越来越抽象。遵循[Semi-supervised classification with graph convolutional networks]中给出的广泛使用的 频谱传播规则,有
- :非线性变换的激活函数,比如 Relu
- : 对应的度矩阵
- :第 l 层的 权重 矩阵
- :结点 对应的邻接矩阵
- :使节点的聚合表示包括其自身的特征
- :单位矩阵
注意,频谱传播规则主要是为无向图设计的,为了将其应用于E-FCG,计算对角矩阵
是 度矩阵的元素,是 的元素。
本文 开发了一种从E-FCG中学习行为级别特征的算法,称为BLFE。在训练阶段,BLFE尝试训练具有两个组成部分的模型:
- 特征提取器,由几个图形卷积层和一个 ReadOut层组成
- 分类器,由全连接(fully-connected)的神经网络实现
在 ReadOut层 中,获得最后一个图形卷积层的输出,并计算矩阵中每一列的总和,即行为级别特征向量:
在训练期间,通过最小化以下 损失函数来迭代更新整个模型:
- :代表基本真值(ground truth)
- :表示预测值
- :表示权重
- 第一项 是交叉熵误差,第二项是为了缓解过度拟合
在测试阶段,BLFE处理E-FCG,并告知相应的应用程序是否恶意。BLFE的详细信息在算法1中给出,其中表示模型中的权重,表示学习率。
一旦对模型进行了良好的训练,就可以使用特征提取器从E-FCG学习行为级别的特征。
借助这些特征,可以将其提供给任何分类器(例如SVM和KNN)或某些高级恶意软件检测方法 进行应用分类。
The BLFE Algorithm
Stage I: Initialization
- 创建包含所有应用程序的语料库;
- 通过 函数嵌入为每个函数找到向量表示;
- 为训练数据集中的应用构建E-FCG;
Stage II: Training
- 在每个epoch:
- 抽样一批 E-FCG
- 使用梯度下降更新 ,即
Stage III: Test
- 对每个应用重复以下操作:
- 为该应用构建E-FCG
- 根据E-FCG做出预测
四、实验评估
Dataset & settings
在本文实验中,使用了一个大型数据集包含43310个样本, 其中7362个样本为恶意样本,其余为良性样本。
为了提取诸如许可要求, intent actions 和API调用之类的静态功能,
- 将每个apk文件解压缩为两个文件:AndroidManifest.xml和classes.dex。
- 通过解析AndroidManifest.xml提取权限要求和意图操作。
- 将classes.dex反编译为一系列smali文件后,获得有关函数调用的信息。
要构建FCG,只需要创建一个邻接矩阵,其中每个元素
- 如果函数 i 调用函数 j ,则 为1,否则为0。
为了获得节点属性,通过将节点属性分配给相应的FCG来构造E-FCG
在实验中,每个函数的矢量表示都是100维的,并且GCN模型具有三个卷积层,每层包含100、100和60个神经元。因此,行为级别特征的矢量表示为60维
为了实现BLFE算法,构建了一个具有 两个隐藏层 的全连接神经网络,该神经网络充当了分类器 并与基于 GCN的特征提取器相连。
Effects of function embedding
为了显示函数嵌入的效果,首先将实验中的函数嵌入2D空间,然后在图4中显示三个函数的表示。函数getLongitude()和getLatitude()都用于获取位置,并且它们通常在应用程序中一起调用。因此,它们在嵌入式 空间中占据着紧密的空间位置。
函数setHomeActionContentDescription()用于设置Home/Up操作的备用描述,它与getLongitude()和getLatitude完全不同。
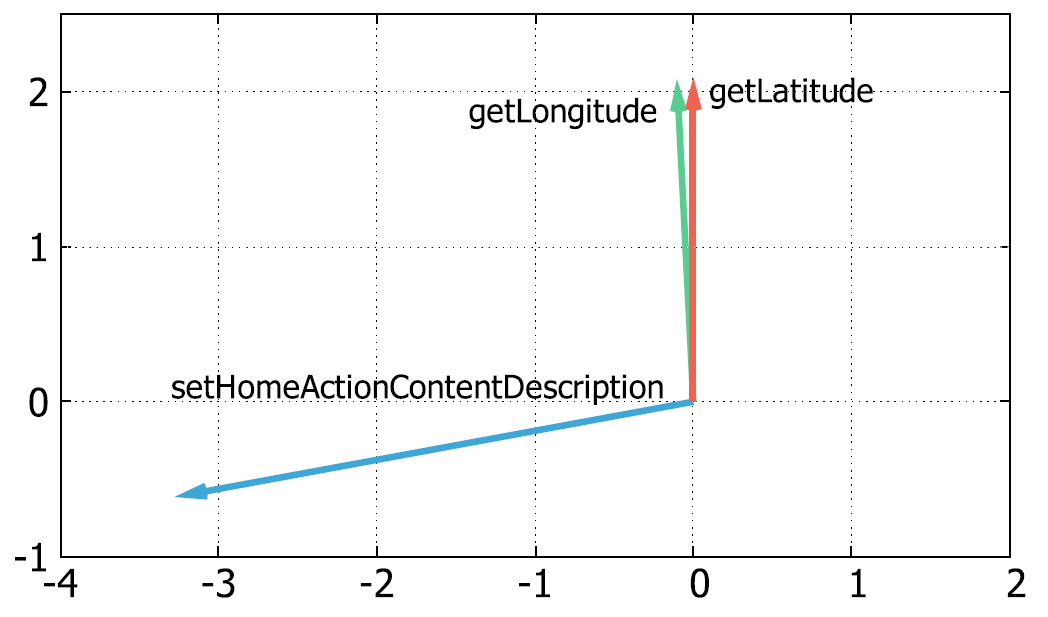
因此,其在嵌入式空间中的位置与getLongitude和getLatitude的位置相距甚远,并且与setHomeActionContentDescription和getLongitude或getLatitude对应的向量之间的角度较大。
Convergence of the BLFE algorithm
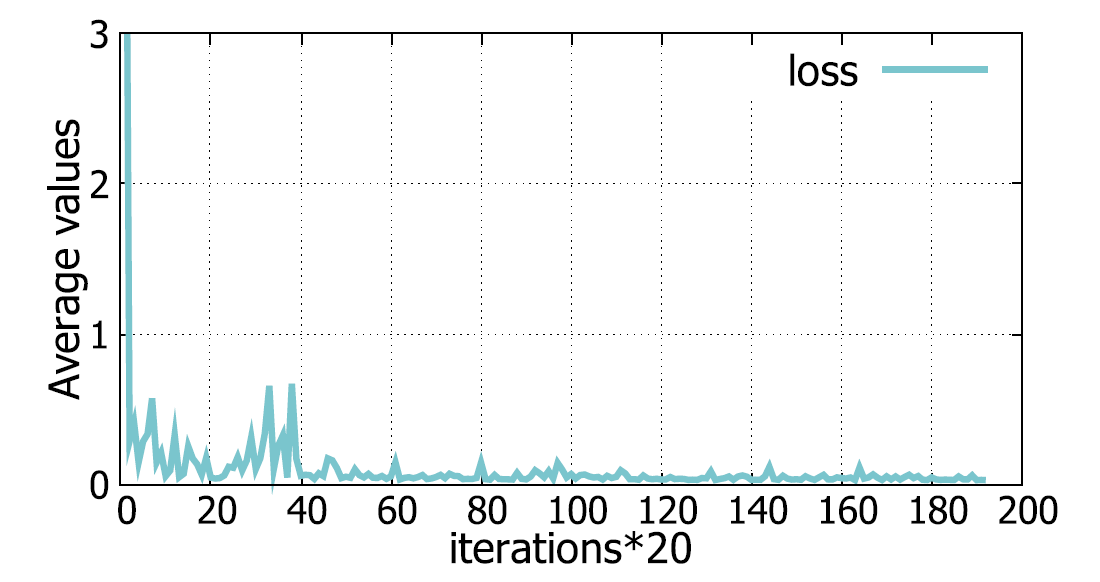
BLFE是一种迭代算法,其收敛性已通过我们的实验验证。为了说明起见,图5描绘了某个实验中的损耗迭代(4)。为了便于描述,图5的垂直轴提供了20次迭代的损耗平均值。因此,水平轴上的每个点代表20次迭代。从该图可以看出,训练期间的损失迅速减少。从水平轴的第100个点开始,损耗一直接近于零,并且BLFE算法收敛。
Detection performance
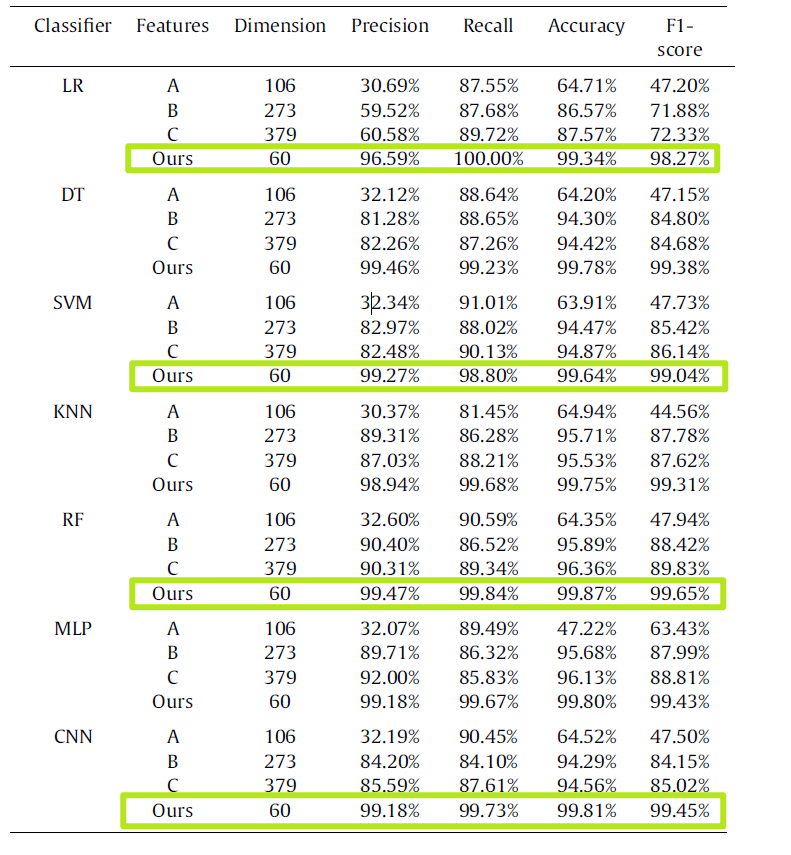
为了评估本方法方法获得的特征,将其应用于七个主流分类器:决策树(DT),k最近邻(KNN),逻辑回归(LR),随机森林(RF),支持向量机(SVM),
多层感知器(MLP)和CNN。
为了进行比较,还考虑了传统的静态功能,包括:
106个敏感的API调用(2)147个权限和126个意图动作(用B表示)的组合,以及
(3)106个敏感API调用,147个权限和126个意图操作(用C表示)的组合。
这些静态功能的效果已在现有文献中得到验证(例如[5,6,8])。
这些静态特征的实验结果也在表1中给出。请注意,我们使用5倍交叉验证来准确评估我们的特征以及特征组A,B和C的性能。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!