FCDetector:Functional code clone detection with syntax and semantics fusion learning
FCDetector
论文题目:(2020-ISSTA)Functional code clone detection with syntax and semantics fusion learning (通过语法和语义融合学习进行功能代码克隆检测)
论文引用:Fang C, Liu Z, Shi Y, et al. Functional code clone detection with syntax and semantics fusion learning[C]//Proceedings of the 29th ACM SIGSOFT International Symposium on Software Testing and Analysis. 2020: 516-527.
工具开源:shiyy123/FCDetector
一、主要内容
本文对C++语言进行克隆检测,本文方法将具有 调用-被调用者关系(caller-callee relationships) 的连接方法视为一种功能(functionality),并且与其他方法没有任何 调用-被调用者关系的方法代表一个功能。
- 首先对代码进行了对句法和语义特征的学习
- 使用 word2vector 分别对语义与语法信息进行提取,转化为向量
- 然后使用有监督的深度进行进行克隆检查。
二、背景介绍
代码克隆检测是许多软件工程任务的基础,例如重构,代码搜索,重用和漏洞检测(bug detection),如果在代码段中标识了漏洞,则需要检查所有克隆的代码段是否存在相同的漏洞,即代码克隆会导致缺陷传播,从而严重影响维护成本。因此,代码克隆检测在软件工程中是重要的,并且已经被广泛研究。
根据不同的相似度级别,代码克隆可分为四种类型:
- Type-1(完全相同的代码段):两个相同的代码段,但空格,空格和注释除外。
- Type-2(重命名/参数化代码):相同的代码段,但变量名称,类型名称,文字名称和函数名称除外。
- Type-3(几乎相同的代码段):两个相似的代码段,但添加或删除了多个语句。
- Type-4(功能克隆):具有相同功能但具有不同代码结构或语法的异构代码段。
本文提出了一种通过语法和语义融合学习(syntax and semantics fusion learning)的方法来检测功能代码克隆。
- 在提取句法和语义特征之前分析方法调用关系(call relationship)。
本文基本思想是通过分析调用图(call graph)和基于嵌入技术 AST和CFG 的句法和语义特征来识别不同代码段的相似功能。
本文分别使用AST和CFG表示语法和语义特征,训练了DNN模型来检测功能性的代码克隆
常用方法
许多现有方法都可以很好地检测出Type-1,Type-2和Type-3代码克隆。但是,在检测Type-4代码克隆方面仍然存在一些未解决的问题。
一种常用的基于语法的代码表示形式是AST(抽象语法树),它可以表示每个语句的语法,在某些情况下,具有不同语法的代码片段可以实现相同的功能,可以将其视为功能克隆。
- 例如,如果直接计算文本相似度,则语句 “ i = i + 1” 和“ i + = 1”是不相同的。但是这两个语句共享相同的AST。典型的方法使用语法解析器将源代码解析为语法树。
另一个常用的基于语义的代码表示形式是PDG(程序依赖图)。 PDG是一种图形表示法,既包含数据依赖关系,又包含控制依赖关系。 PDG可以将代码片段划分为基本代码块并表征其结构。具有不同结构的相同功能代码段可以检测为克隆。
- 例如,for 和 while循环结构具有不同的AST,但它们的PDG相同。
- 典型的方法包括Duplix 和GPLAG ,它们通过比较代码对的同构图来检测克隆。
现有方法缺陷
基于语法的方法和基于语义的方法都有其局限性。
AST可以表示源代码的抽象语法,但它无法捕获语句之间的控制流;PDG中的每个节点都是一个基本代码块(即至少是一个语句),与AST相比PDG太粗糙了,而粒度不正确可能会导致代码块内部缺少详细信息。
- 例如,对于语句“ int a = b + c”,AST节点为int,=,+,a,b,c。
- 但是,此总体声明在PDG的表现为节点。此外,用于复杂代码的PDG可能非常复杂,并且图同构的计算不可扩展
此外,AST通常用于表示一种方法,而PDG用于表示整个文件。
- 大多数现有方法在单个方法或单个文件的粒度上比较代码相似性。
- 而一个功能(functionality)可能包含多种方法,也即单个方法可能无法表达功能的完整含义。
- 同一个文件可能包含一些不相关的功能(functionality),因此这些粒度级别可能不是功能克隆检测的最佳选择。
本文方法
为了克服上述限制,本文使用调用图(call graph)来组合相关方法,因此粒度是灵活的,并且取决于实际功能的粒度。此外使用CFG(Control Flow Graph,控制流图)来表示代码结构,而不是采用更复杂的PDG。
- CFG可以捕获与 PDG 相同的控制依赖性,并且可以克服耗时的障碍。
- 每种方法都可以生成为AST和CFG
- 由于 AST 和 CFG 的表示形式具有不同的结构,因此无法直接融合,因此本文应用嵌入学习技术(embedding learning techniques) 来生成固定长度的连续值向量(fixed-length continuous-valued vectors)。这些向量是线性结构,因此可以有效地融合句法和语义信息,特别适合于深度学习模型。
- 然后对大型现实数据集的广泛评估显示了对 功能性代码克隆检测的的结果。
三、提出背景
典型的代码克隆检测方法通常遵循三个步骤:
- 代码预处理:删除源代码中不相关的内容,例如注释;
- 代码表示:从源代码中提取不同种类的抽象,例如AST(抽象语法树)和PDG(程序依赖图)
- 代码相似度比较:计算两个源代码之间的距离;当此距离达到阈值时,将检测到代码克隆。
由于代码表示形式对功能代码克隆的检测具有至关重要的作用,因此本文主要介绍语法表示形式AST和语义表示形式CFG的背景,而这些树和图结构不能直接用于网络,简要讨论单词嵌入和图嵌入的背景。
Abstract Syntax Tree
抽象句法树(AST)是用编程语言编写的源代码抽象句法结构的树表示,此树定义了源代码的结构,通过操纵这棵树研究人员可以精确地定位声明语句、赋值语句、操作语句、实现分析、优化和更改代码等操作。
Control Flow Graph
控制流图(CFG)是使用图形表示法的表示,在执行过程中可能会遍历程序的所有路径。 在每个CFG中都有一个包含几个代码语句的基本块,CFG可以轻松每个基本块的信息,它可以轻松找到程序中无法访问的代码,并且在控制流程图中易于检测到诸如循环之类的语法结构。
Word Embedding
词嵌入(Word embedding)是自然语言处理(NLP)中语言模型和表示学习技术的统称
- 将具有所有单词数量的高维空间嵌入到维数较低的连续向量空间中,并将每个单词或短语映射到实数字段上的向量中。
- 由于源代码和自然语言在某些方面相似,因此许多方法尝试使用词嵌入技术来处理源代码。
Graph Embedding
图通常是高维的并且难以处理,比如社交网络,流程图和通信网络之类的。现在已经有图形嵌入算法(graph embedding algorithms)作为降维技术的一部分,大多数图形嵌入技术旨在将图形的每个节点转换为向量。
由于 CFG 是典型的图形,因此一些现有方法尝试使用图形嵌入技术进行代码表示,例如,Tufano 使用一种图形嵌入技术来表示语义特征。在本文中比较了几种图形嵌入技术,并选择了最有效的 CFG 表示技术。
Motivating Example
为了检测功能性代码克隆,首先提取调用图(call graph)并分析每个文件的功能,将具有调用于被调用者关系的方法视为一种功能。与其他方法没有任何 调用于被调用者关系 的方法可以视为独立功能。
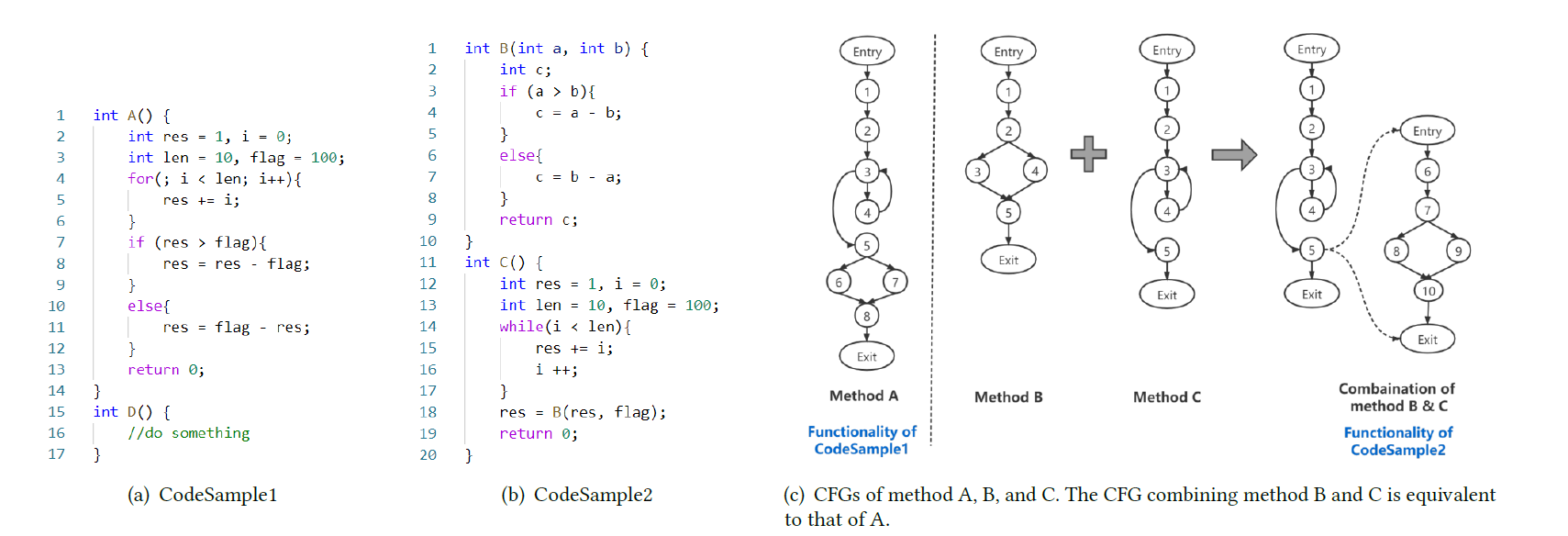
- 对于图1(a)和1(b)中所示的两个源代码文件,CodeSample1 中的方法A实现了简单的计算功能。
- 在CodeSample2中,方法C调用方法B,它们的组合实现与方法A相同的功能。
- 如图1(c)所示,如果我们以方法粒度检测代码克隆,我们可以看到方法A的CFG, B和C在结构上不同。
但是,根据调用图组合方法B和C后,可以发现组合的控制流与方法A等效。因此,考虑方法之间的调用图后,我们可以得出结论:CodeSample1 中的方法A和方法A中的方法A相同—— CodeSample2中方法B和C的组合是功能克隆。
如果我们仅在方法级别检测功能,则结果将产生误导。此外,以文件粒度检测功能克隆也是不合适的。
- 注意:CodeSample1中有一个方法D,与方法A无关,直接将它们组合在一起是不合理的。因此,更适合在捕获代码特征之前提取调用图并识别功能。
确定每个文件的功能后,通过分析AST和CFG来检测功能代码克隆。
CFG 可以反映语句的结构并显示控制流程,控制流是抽象的,无法清楚地识别CFG中节点之间的差异。
- 因此通过语法和语义融合学习来检测代码克隆。
- 可以通过分析AST来捕获语法。
例如,如果在方法A中将for循环中的符号 + =”更改为 “ * =”,则功能将完全更改。
- 但是,由于CFG结构未更改,因此,如果仅考虑CFG,则将导致假阳性结果。
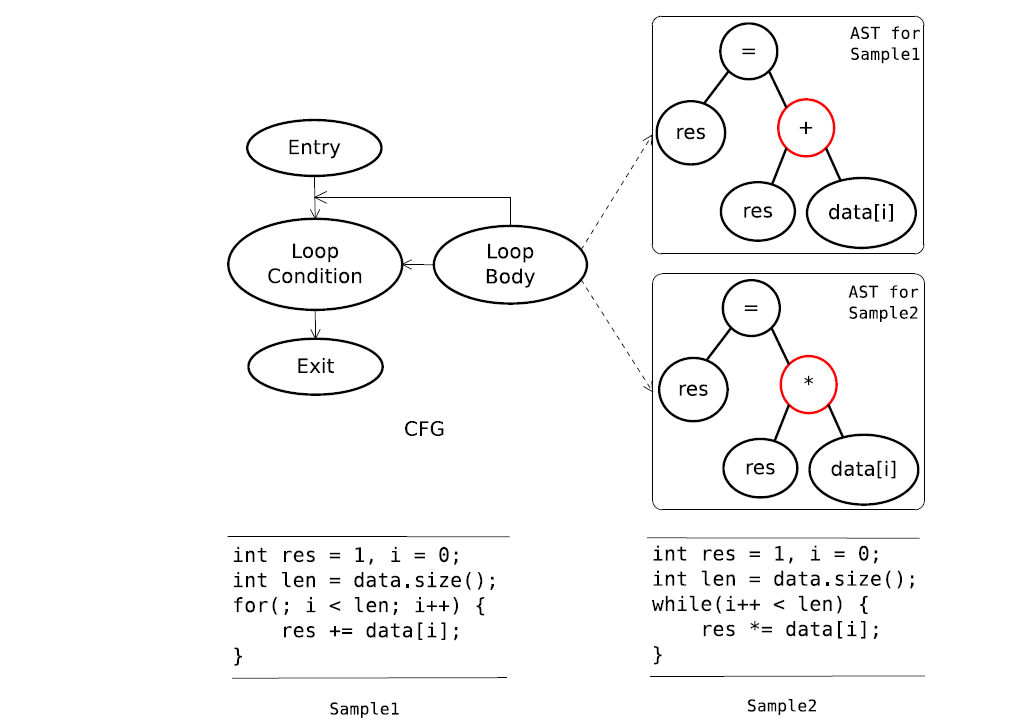
这两个代码段之间的差异位于两个循环主体的AST内部,如图2所示。因此,有必要同时考虑语法和语义以进行功能代码克隆检测。
此外,某些代码结构可以实现相同的功能,但是AST结构完全不同。
- 例如,for循环和递归结构都可以计算给定输入的阶乘,而这两个代码结构的AST完全不同。
- 但是,两个代码段的过程间控制流图非常相似,两者都包含一个循环。
由于我们的方法不仅分析AST,而且利用过程间信息(例如调用图),因此本文方法可有效检测此类过程间代码克隆。
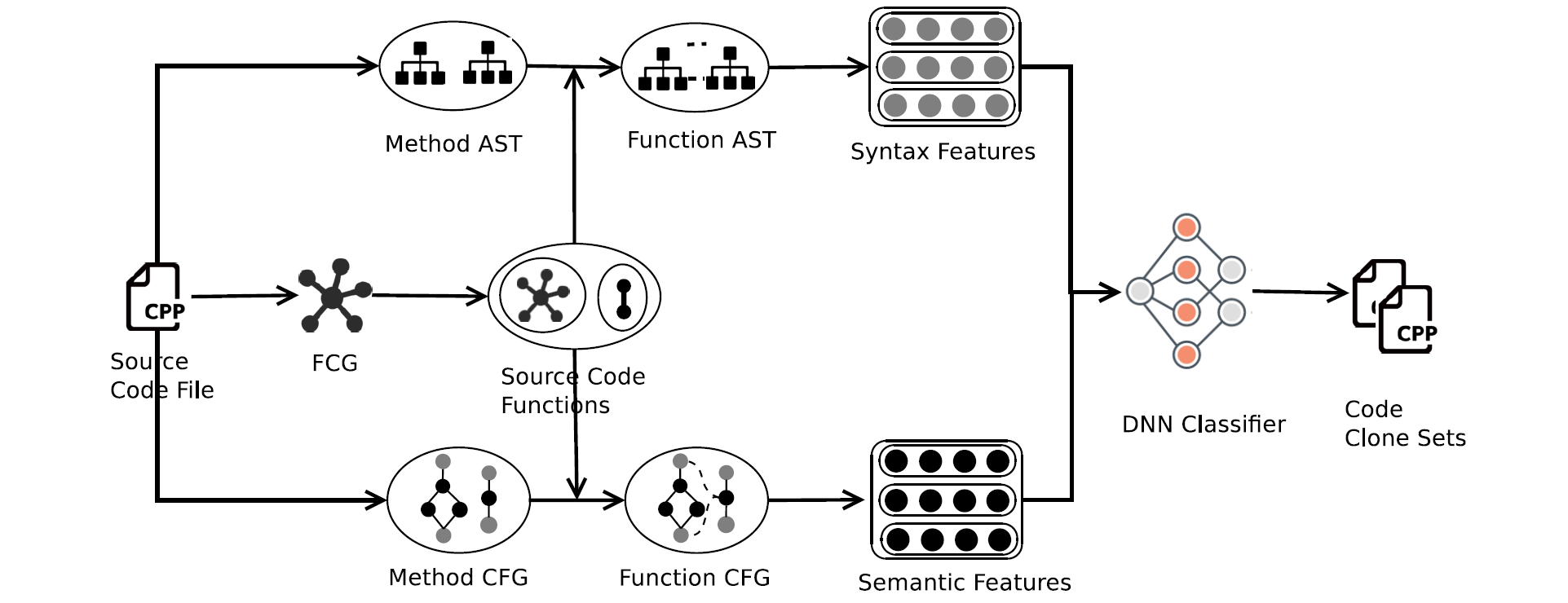
四、本文方法
本文提出的方法包括以下三个组成部分:
1、Identify the functionality with call graph(通过调用图识别功能):为了确定每个源代码文件中的功能,提取了调用图以分析方法之间的调用者与被调用者之间的关系。将具有 caller-callee 关系的方法作为功能组合在一起。其他方法中没有任何 caller-callee 关系的方法被认为是独立的功能。
2、Extract syntactic and semantic representations (提取句法和语义表示):为了捕获代码特征,需要提取AST和CFG来表示语法和语义。
- 首先,提取每种方法的AST和CFG
- 然后根据调用图(call graph)将相关方法的AST和CFG结合起来,组合的 AST / CFG代表单独的功能
- 最后,使用嵌入技术(embedding techniques)将AST和CFG编码为语法和语义特征向量。
3、Train a DNN model (训练DNN模型):为了将功能克隆检测转换为二进制分类,本文训练了带有标记数据的DNN分类器模型。
- 当遇到两个新函数时,提取并融合特征向量,并使用经过训练的模型来预测它们是否为代码克隆。
Identifying the Functionality with Call Graph
本文提取调用图以标识每个源代码文件中的功能,调用图表示程序中方法之间的调用关系。
- 每个节点表示一个方法,每个边沿(f,g)表示该方法 f 调用方法 g。
- 对于输入源代码文件,它们中的所有语句都标记有全局唯一ID,可以将其视为标识符。
调用方与被调用方的关系以三元组的形式表示:⟨callerId, statement Id, calleeId⟩
- callerId 和 calleeId是相应方法的语句ID, statementId是 call语句的ID。
例如,在图1(b)中,方法C调用了方法B。因此,调用方语句在第10行中为int C(),调用语句为c = B(a,b,flag);
在第14行中,被调用者语句在第1行中是int B(int a,int b,bool标志)。根据调用图表达式,我们可以获得连接的方法作为功能。
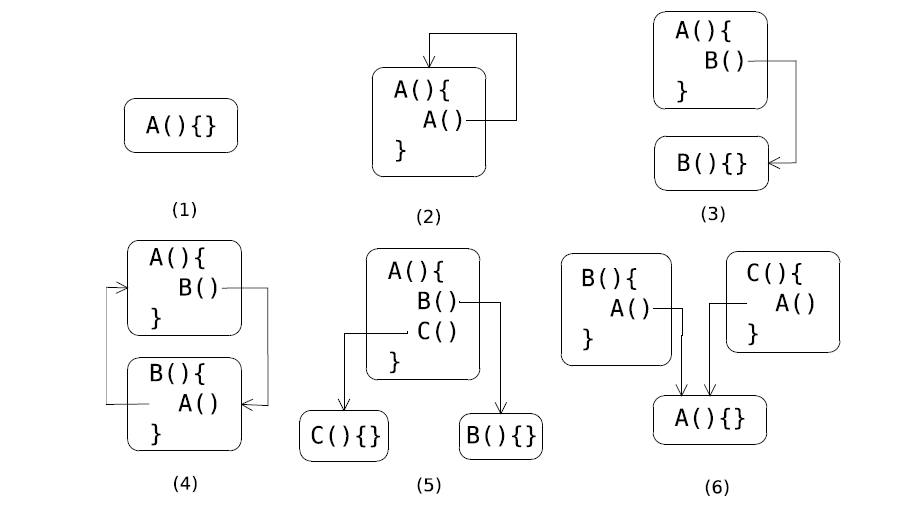
为了说明 呼叫者与被呼叫者 之间的关系,本文列出了六个调用图实例,这六个静态呼叫图实例是最常用的呼叫图:
- 在情况(1)中,存在一种功能,其中包括方法A;
- 在情况(2)中,方法A对其自身进行递归调用,并且还存在一个功能,其中包含单个方法A;
- 在情况(3)中,存在方法A调用方法B的情况,并且该情况具有包括方法A和方法B的功能。
- 在情况(4)中,方法A和方法B相互调用,并且具有包括方法A和方法B的功能。
- 在情况(5)中,方法A调用方法B,方法A调用方法C,但也只有一个功能,该功能包括方法A,B和C。
- 在情况(6)中,方法B调用方法A,方法C调用方法A。有两种功能,一种包括方法{A,B},另一种包括方法{A,C}。
Extracting Syntactic and Semantic Representations
AST Representation
假设 C 是代码段C,而Nroot是其对应的AST入口节点。为了提取C的语法表示形式,首先从Nroot开始,并按顺序迭代遍历AST的所有节点。
- 在每个AST节点中,都有一个标识符,例如符号和变量名
- 在此过程中生成的标识符序列可用于表示 C 的语法信息:Seq = {ident1, ident2, . . . , identn }
在不同的程序中,变量的命名可能会有很大的不同。因此,变量名称可能会对功能克隆检测产生影响。给定一个标识符序列 Seq:
- 首先通过将常量值和变量替换为其类型来标准化它:⟨int⟩,⟨double⟩,⟨char⟩和⟨string⟩
- 并添加一个全局自增数,例如⟨int1⟩。
- 当遇到小数时,无论是“ float”还是“ double”,将它们统一为“ double”。
提取每种方法的AST并获得相应的标识符序列Seq,
- 根据调用图提取的呼叫者与被调用者之间的关系,将每个连接方法的AST组合为一组AST。
- 对于具有连接的方法,使用其AST的集合来表示功能的语法。
- 同样,对于没有主叫方关系的方法,使用相应的AST表示功能的语法。
CFG Representation
与AST相比,CFG捕获了更全面的语义信息,例如分支和循环。尽管CFG还包含基本块级别的语法信息,但是与从AST级别以标识符级别的粒度提取的语法信息相比,CFG的表示对于检测功能克隆而言过于粗糙,因此专注于提取语义
给定一个代码段C,为每种方法提取其 CFG G =(V,E),其中V是一组顶点,E是一组边,每个顶点都包含一个源代码声明,并且边表示该声明的控制流。
- 首先提取每种方法的CFG并获得相应的图G。然后根据调用图关系连接CFG并生成一个更大的CFG来表示功能。
具体的连接规则如下:
- 在情况(1)中,功能的 CFG与方法的CFG相同;
- 在情况(2)中,功能的CFG也与方法的CFG相同,并且从调用者语句向方法的入口节点添加了一条边;
- 在情况(3)中,首先需要添加方法A和B的CFG,然后获得方法A中功能调用语句的父节点列表和子节点列表,然后将所有节点都指向该条目方法B中的节点,所有子节点都指向方法B中的出口节点;
- 情况(4),(5)与情况(3)类似,并且另外修改了与另一个函数调用语句相关的边;
- 在情况(6)中,有两个功能,因此我们需要分别处理这两个功能。
Embedding Syntactic Feature of Functionality
嵌入功能的语法特征
源代码中的每个方法都表示为一系列标识符,使用Word2vec 对语法特征进行编码。
- 词嵌入是语言模型的通用术语,它会将高维空间词嵌入到维数较低的连续向量空间中,其中每个词都映射到实数字段中的向量。
如图所示,为了对每种方法的语法特征进行编码,将每种方法的归一化标识符序列Seq合并为语料库。Word2vec使用语料库作为训练模型的输入,并输出一组固定长度的矢量来表示每个AST节点。
为了获得每种方法的语法特征向量,将平均池(average pooling)应用于每种方法中所有标识符的向量,在此步骤之后,每种方法的语法信息都表示为固定长度的特征向量
mv = average(hi ), i = 1, . . . , N
- 其中hi是每个标识符的特征向量,
然后对每种功能(即连接的方法)应用平均池化以产生相应的句法特征,每个功能的语法信息表示为固定长度的特征向量。
v = average(mvi ), i = 1, . . . , N
- 其中mvi是每种方法的语法特征向量。
Embedding Semantic Feature of Functionality
嵌入功能的语义特征
使用图嵌入技术对 CFG 进行编码,
- 图形嵌入是使用低维且密集的矢量来表示图形中的每个节点,向量表示可以反映图中的结构。
本质上,两个节点共享的相邻节点越多(即,两个节点的上下文越相似),则两个节点的对应向量越接近。
图嵌入后,每种方法都表示为固定长度的特征向量,有许多图形嵌入技术,例如Graph2vec,HOPE ,SDNE 和Node2vec 。
与其他图嵌入技术不同,Graph2vec 可以生成一个向量来反映整个图的特征,比较了不同的嵌入技术,表4中的结果表明Graph2vec表现出最佳的F1值。
对于每种方法,本文使用 Graph2vec 生成的特征向量来表示语义特征向量;对于每种功能,根据调用图连接连接方法的所有CFGs,根据连接规则可以获得连接方法的连接CFG。
- 然后在此功能的连接CFG上应用 图嵌入,将连接的CFG转换为特征向量。
Training a DNN Model
为了检测功能代码克隆,可以按照功能上的粒度直接比较语法和语义编码的联合特征向量之间的欧几里得距离。
- 这种基于距离的方法已在先前的工作中用于检测语法克隆,例如Deckard [9]。
但是,在本文情况下直接计算距离不起作用,因为提取的节点特征向量之间的距离是不规则的,因为每个维度的权重都不同,并且难以手动设置适当的阈值以区分功能代码克隆,如图所示。
特征向量之间的欧式距离
- 蓝线表示相似代码段之间的距离,红线代表不同代码段之间的距离。
- 横轴是代码段的ID
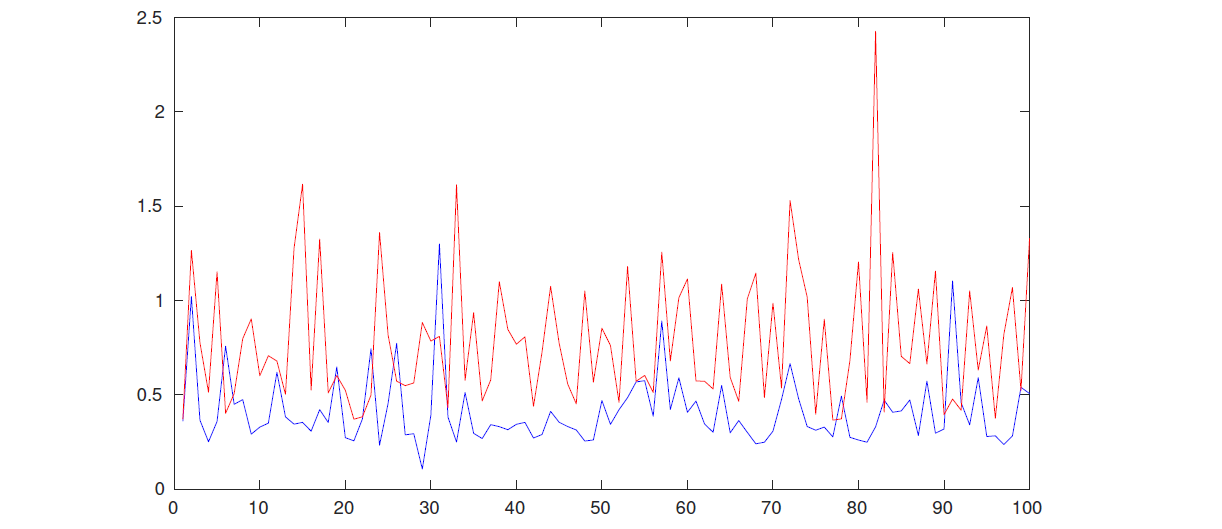
为了解决这个问题,本文使用深度学习模型,因为该模型可以有效地检测代码片段之间的功能克隆。
- 特别是,我们融合了句法和语义特征向量作为输入来训练前馈神经网络[32],并将代码克隆检测转换为模型末尾的softmax层的二进制分类。
没有选择特定的距离度量或设置克隆检测的阈值,而是采用深度学习技术进行功能代码克隆检测,该技术可以从融合特征向量中自动学习潜在代码特征。
DNN模型的体系结构如图7所示,它由四个组件组成。
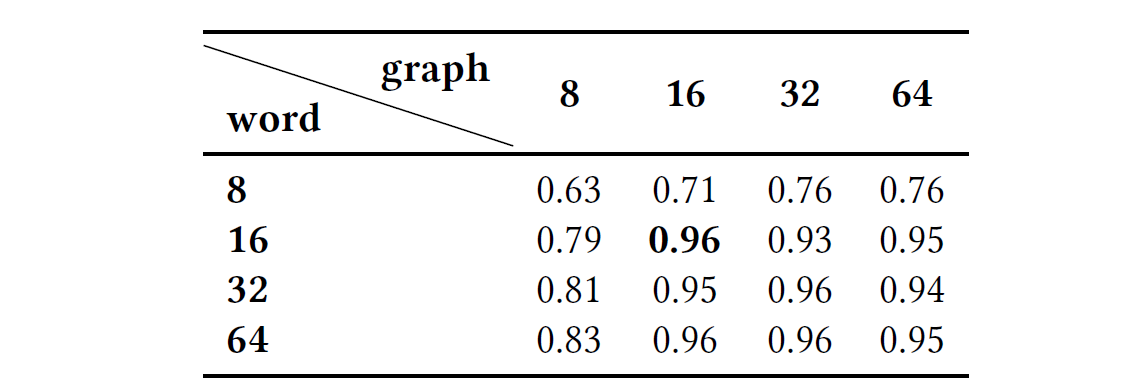
- 首先根据获得语法和语义特征,并将这两个特征串联在一起作为模型的输入,其中语法和语义信息都用16 维向量表示。
- 为了获得AST和CFG的单词嵌入和图形嵌入,使用 Word2vec 和Graph2vec生成长度为{4,8,16,32} 的单词嵌入和长度为{4,8,16,32} 的图形嵌入。
根据实验,本文选择向量长度为16,简而言之,较长的向量将增加训练时间,而较短的向量将无法捕获足够的代码特征。
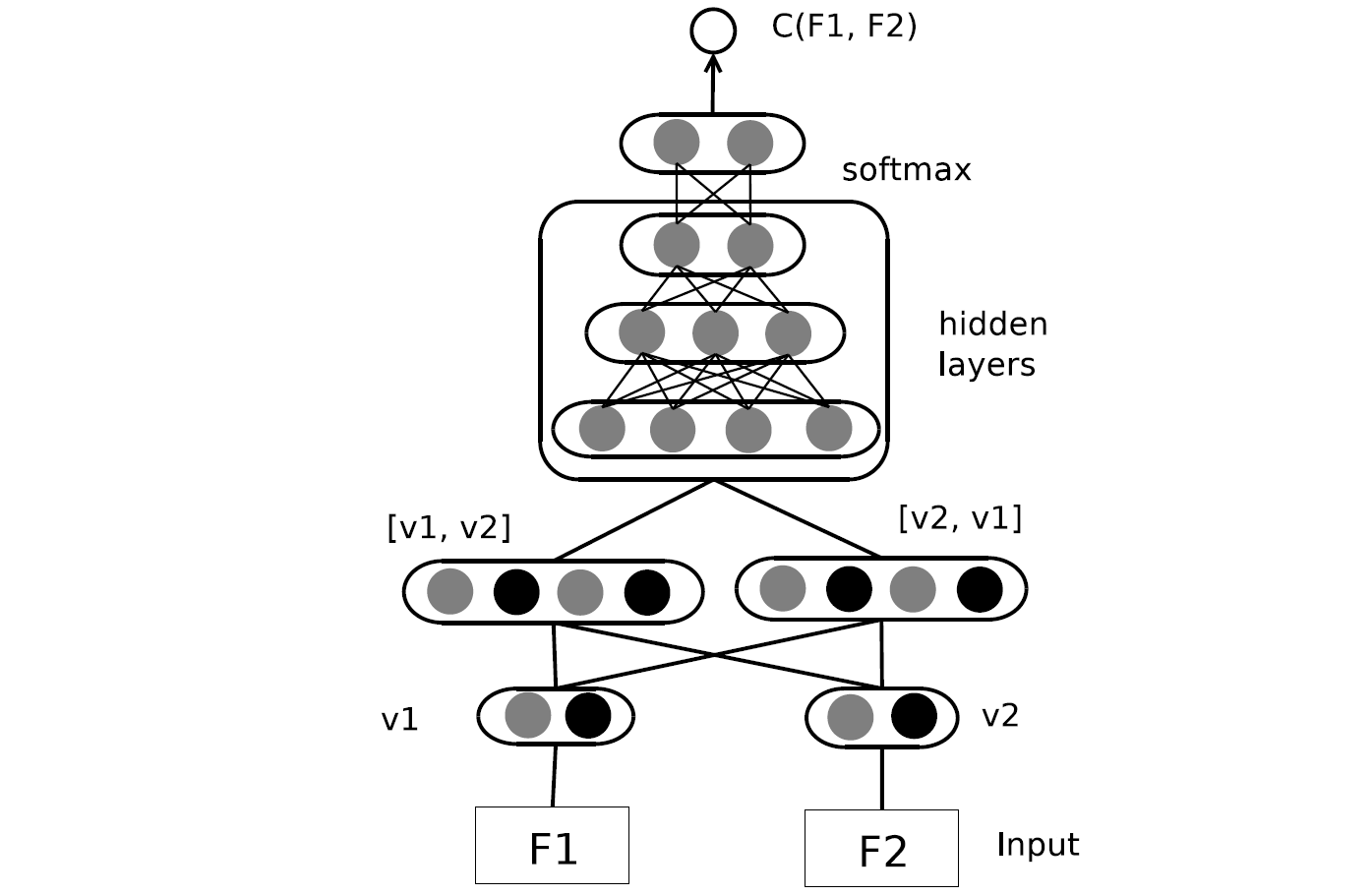
使用一对代码功能(code features)来表示这两个功能是否为克隆。
- 输入向量包含三个部分:用于第一功能的融合特征向量V1、用于第二功能的融合特征向量V2、标签。
融合特征向量包含 16 维语法向量和16维语义向量,标签是布尔值,其中0表示非克隆对,而1表示克隆对。
因此,输入的总尺寸为65(32 + 32 + 1)。
在 [V1,V2] 和 [V2,V1] 这两个功能的融合特征的顺序可能会影响分类结果。
- 输入两个要素之前放置一个完全连接的层。
- 然后,隐藏层使用线性变换,然后再压缩非线性,以将输入变换为二进制分类层中的神经节点,该步骤可以提供复杂且非线性的假设模型,该模型具有权重矩阵W以适合训练集。
- 在下一个组件中,该模型然后使用反向传播根据训练集调整权重矩阵W。
- 最后,有一个softmax层,它将功能克隆检测转换为分类任务。
假设有两个代码融合向量V1和V2,并且它们的距离由d = | v1- v2 |来度量句法和语义上的相关性。然后将输出视为它们的相似性:
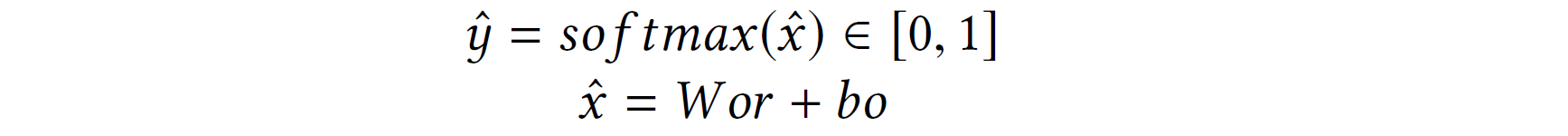
其中 Wor 是隐藏层的权重矩阵:
- 该模型使用交叉熵损失函数,该函数在更新权重方面要优于均方损失函数,训练模型的目的是使损失最小化。
- 选择AdamOptimizer ,因为它可以将学习速率控制在一定范围内,并且参数相对稳定。
- 该模型是DNN分类器,具有两个类。
在优化所有参数之后,将存储经过训练的模型,对于新的代码片段应将其预处理为语法和语义向量,然后将其馈入模型以进行预测,输出为1或0,代表克隆或非克隆代码对
五、实验评估
数据集:OJClone,一个教学程序在线判断系统,主要包括C / C ++源代码。OJClone包含104个编程任务,每个任务包含500个由不同学生提交的源代码文件
- 对于同一任务,由不同学生提交的代码文件被视为功能代码克隆(functional code clones)。每个代码段都可以用(s1,s2,y)表示
- 其中s1和s2是两个代码段,而y是它们的代码克隆标签。
- y的值为{0,1}。
- 如果s1和s2解决同一任务,则y的值为0。
- 如果s1和s2解决不同的任务,则y的值为1。
- 从104个问题中选择 前35个问题,每个问题有100个源文件
为每个任务生成了100 * 100个克隆对,并为两个不同的任务生成了100 * 100个非克隆对。
- 当问题集超过两个时,非克隆对将远远多于克隆对,而数据的不平衡会影响实验结果,因此本文采用欠采样来平衡克隆对和非克隆对。
- 将数据集随机分为两部分,分别用于训练和测试的比例分别为80%和20%。使用AdamOptimizer,训练率为0.001,训练时期为10000。
实验平台
具有8个内核的2.4GHz CPU和NVIDIA GeForce GTX 1080 GPU的服务器。
评估标准
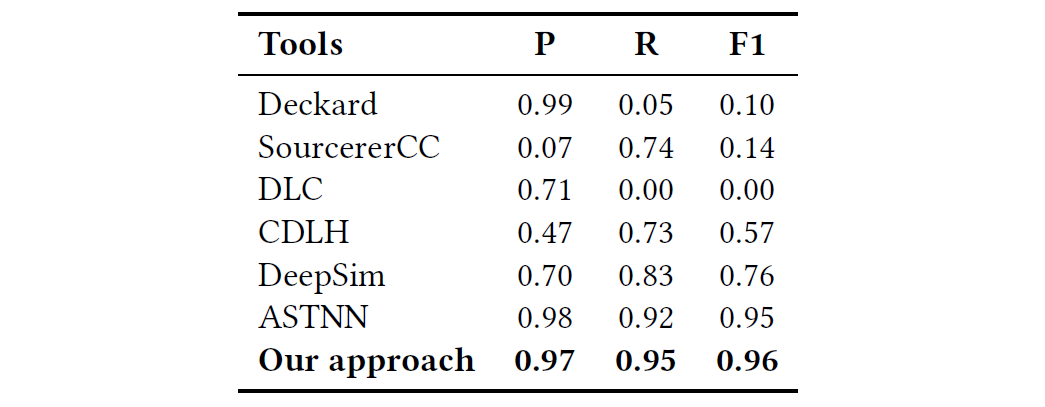
RQ1:与最新方法相比,本文方法在功能代码克隆检测中的表现如何?
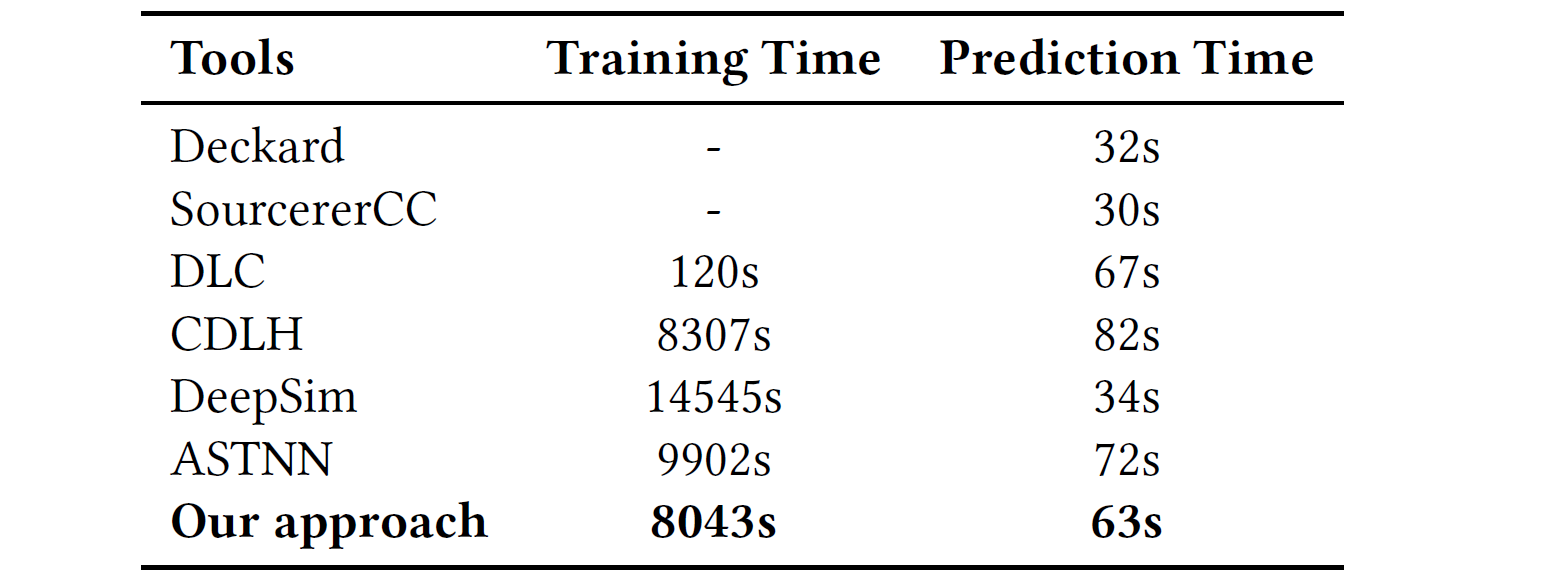
为了评估我们的方法的性能,我们将我们的方法与几种最新的代码克隆方法进行了比较,如下所示:
- Deckard是一种基于语法树的方法,它使用欧几里得距离来比较代码片段之间的相似性以检测代码克隆。
- SourcererCC,这是一种基于令牌的代码克隆检测器,适用于非常大的代码库和Internet规模的项目存储库。
将源代码转换为定义的树结构,并使用卷积神经网络学习无监督的深层特征稍,将其简称为DLC:
- CDLH,一种深度学习方法,用于学习代码克隆的语法功能,它将代码克隆检测转换为对源代码哈希特性的监督学习。
- DeepSim,这是一种基于语义的方法,将受监督的深度学习应用于度量功能代码的相似性。
- ASTNN,一种基于最新神经网络的源代码表示形式,用于源代码分类和代码克隆检测。
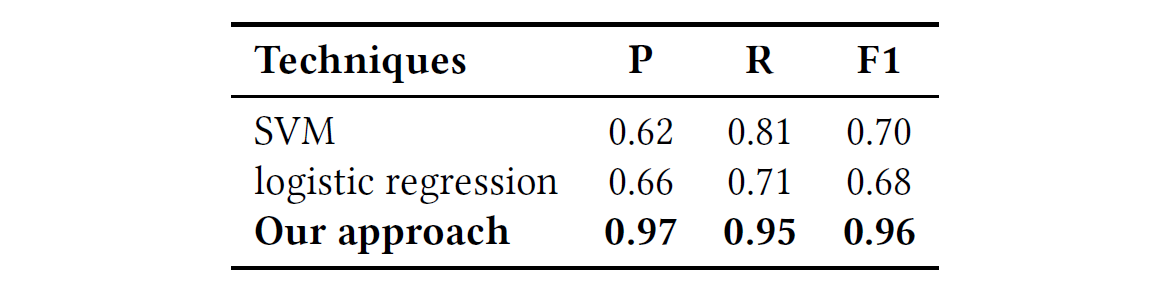
在精度(P),召回率(R)和F1度量(F1)方面将我们的方法与这些代码克隆检测方法进行了比较。
- 因为数据集主要属于功能代码克隆,所以检测性能可以表明这些方法检测功能克隆的能力。
六、本文评价
本文提出了用于功能识别的细粒度源代码。
- 将具有caller-callee关系的方法视为功能的实现。
- 本文方法据说是首先在功能代码克隆检测中考虑调用图(call graph)的。 提出了一种嵌入了对句法和语义特征的代码表示形
- 结合语法和语义信息,可以精确检测功能代码克隆。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!